

Rittman Mead Consulting

OAS / DV & HR Reporting (A Learning Experience)

I wanted to share a personal learning experience around HR reporting using Oracle Analytics Server (OAS) and Data Visualisation (DV). In my experience, more often than not, the old school Oracle BI development tool skillset (BI Apps / OBIEE / BI Publisher) usually reside in the IT department. Often IT cannot respond quickly enough to develop new HR reports in line with increasing demand from HR for data. In addition, HR Professionals want to access the data themselves or at least be served it from people who report directly to them. After all they are the individuals who both need and fully understand the data and also in many cases are the only people who should be accessing it. Perhaps OAS has a part to play in improving this situation and give HR better access to HR/Pay data? My target audience for this blog is HR professionals and those that support the both technical and non-technical.
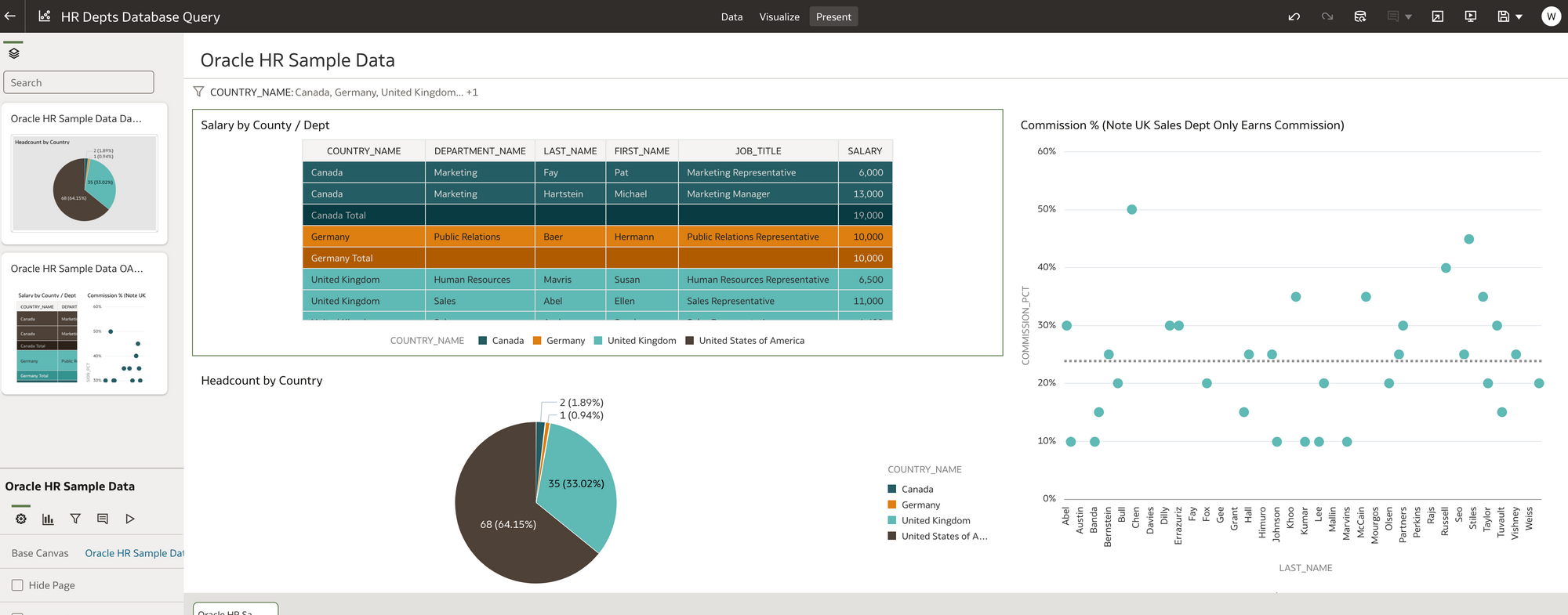 Example of Some DV reports built using Oracle Sample HR Schema
Example of Some DV reports built using Oracle Sample HR SchemaBy explaining the steps I have taken during my learning experience (below), my intention is to illustrate the capability and flexibility of Oracle Analytics Server in both quickly accessing and presenting HR data while at the same time showing some of the touch points between the functional and more technical aspects of the tool. Finally I wanted to build the environment myself locally and use existing resources that are free to use. The only cost should be the time taken to learn!
Personally I am from an Oracle BI Apps / OBIEE background, so I wasn't really that familiar with OAS and the DV tool. I set myself the target of getting a working OAS system locally and then getting hold of some HR data and then presenting some basic HR reports in DV, Including some basic payroll metrics. How hard can it be!?
The purpose of this blog is to assist an individual who has Admin rights to a machine and some technical skills to quickly get some data in front of HR for comment and feedback (your going to need at least 16GB ram to get docker images running). The intention was also to give visibility on key components of the application if you are a newbie to OAS. And Finally to show where the HR team can get involved into accessing and improving data quality quicker than with the older BI toolset. Please Note the blog is not intended to show complex data modelling of ERP/Fusion Oracle HR or Payroll for reporting purposes.
WHAT I DID
1) I used Docker Desktop to create a container for Oracle Database R19.3 and also a container for OAS 642. (the R19.3 Db container was sourced from Oracle Github Docker Images and OAS from Github gianniceresa Oracle Analytics 6.4 folder Note you still need the binaries from Oracle to perform the installation)
2) I used the Oracle HR sample schema provided in an oracle database install as the Oracle datasource. $ORACLE_HOME/demo/schema/human_resources. The schema and data was imported into the docker container for the R19.3 database.
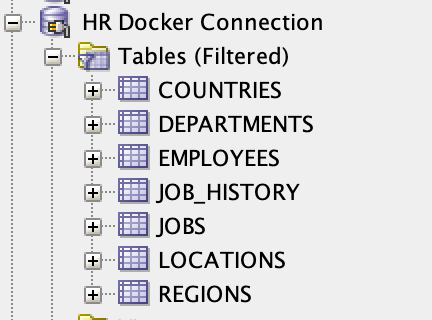 Connection shown to Docker DB in SQLDeveloper for illustration of schema
Connection shown to Docker DB in SQLDeveloper for illustration of schema3) In OAS I made a Database connection to the docker database container containing the HR schema. I called the connection 'HR' as I made the connection using the HR database user.
Create Connection --> Oracle Database (I used basic connect)
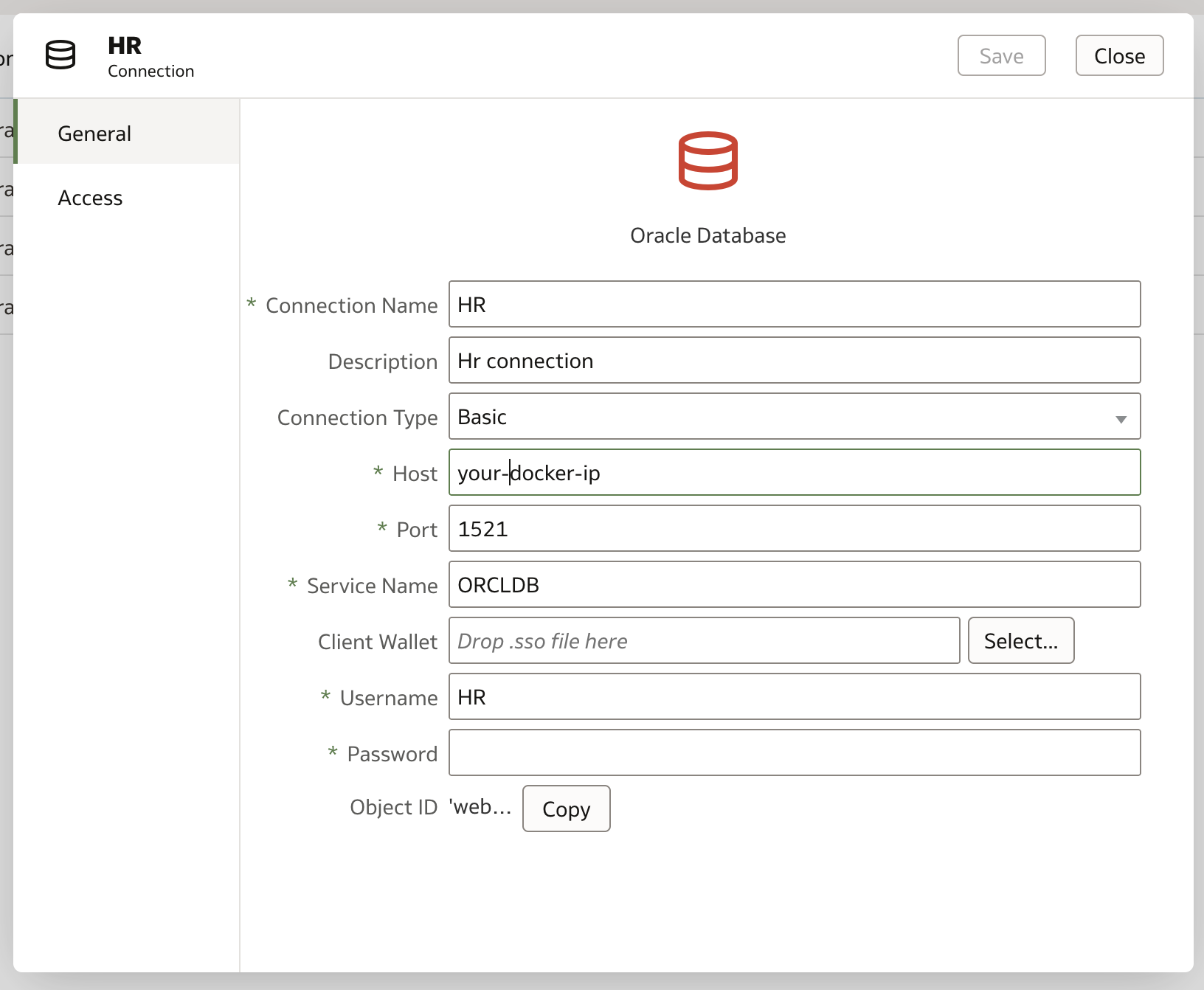 The Oracle Database Connection
The Oracle Database ConnectionNote to make the connection in the connection field host you need to put the IP of the docker image so use command below to find (note db19r1 was the name of my db container)
docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' db19r1
4) I created a new OAS dataset using the HR connection
 HR Connection to create dataset denoted by Red Icon
HR Connection to create dataset denoted by Red IconI used manual SQL queries to select all data for each of the tables -
e-g Select * from HR.EMPLOYEES - Note. I could have just dragged and dropped the entire Employee table, however, I created as a SQL query in case I wanted to be more specific with data going forward and be able to alter or change the queries.
Queries / tables are then joined them together in the Join Diagram.
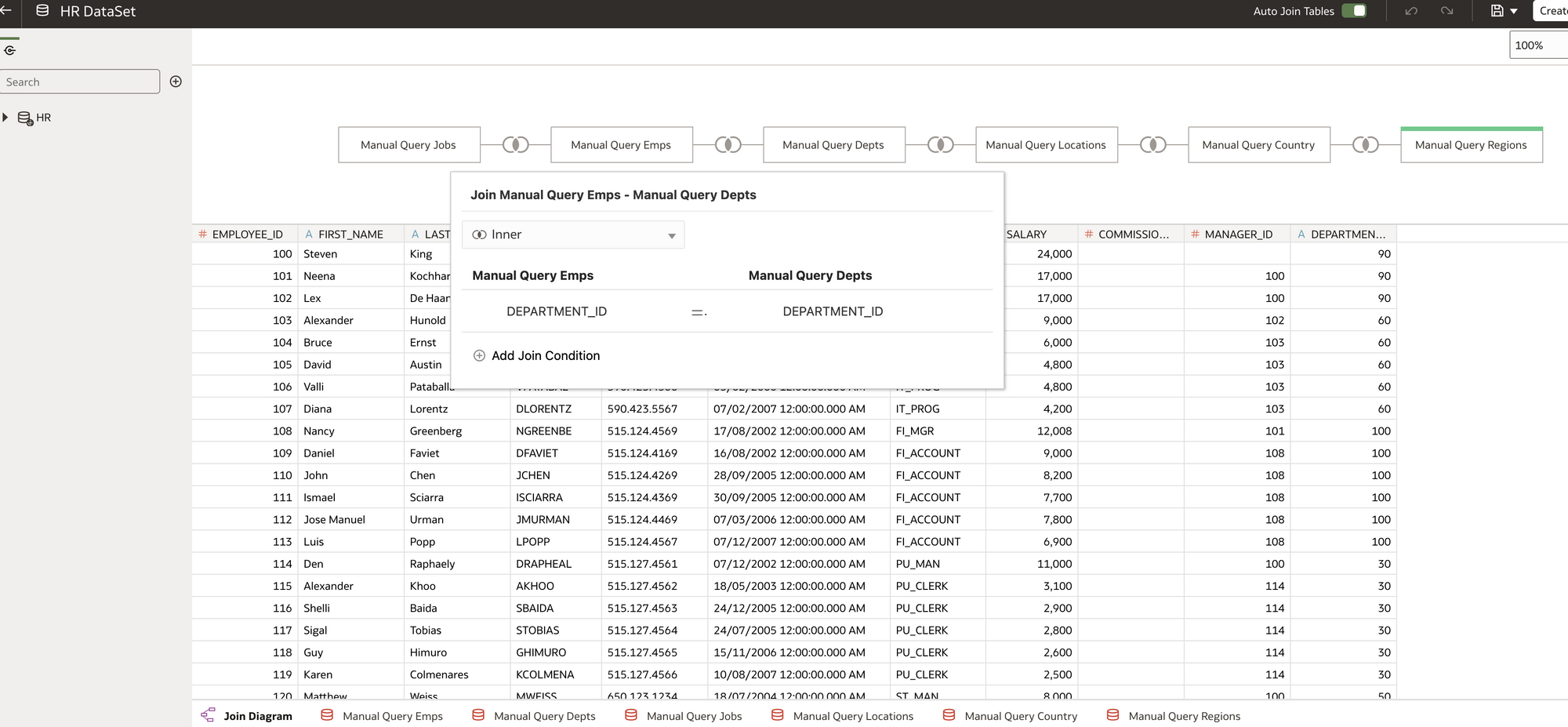 Join Diagram Example
Join Diagram ExampleMake sure you certify and grant access to the dataset in line with you security requirements. As this is just a sample set of data from Oracle we don't need to worry about this for now but it is worth mentioning.
5) I wrote some basic reports in DV using the newly created HR Dataset.
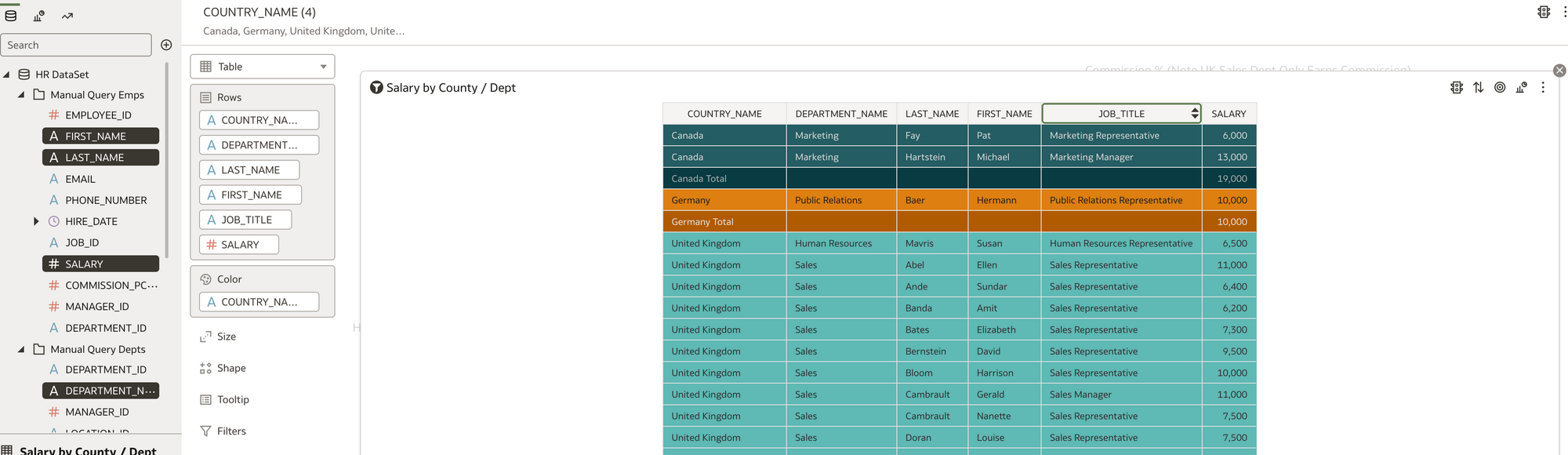 Simple Table Vis. Salary By County and Dept with Totals
Simple Table Vis. Salary By County and Dept with Totals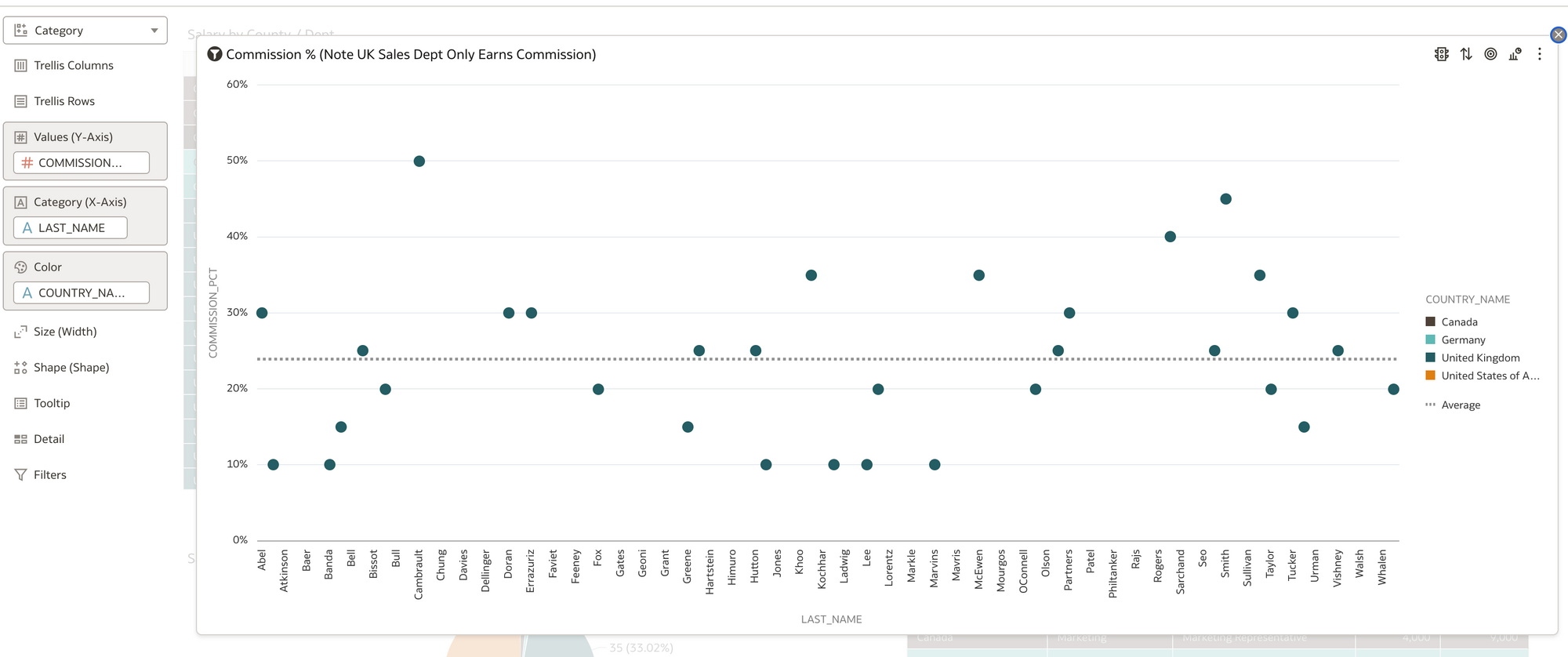 Simple Category Vis. UK Sales Dept Commission % by Person (ref line shown as Average)
Simple Category Vis. UK Sales Dept Commission % by Person (ref line shown as Average)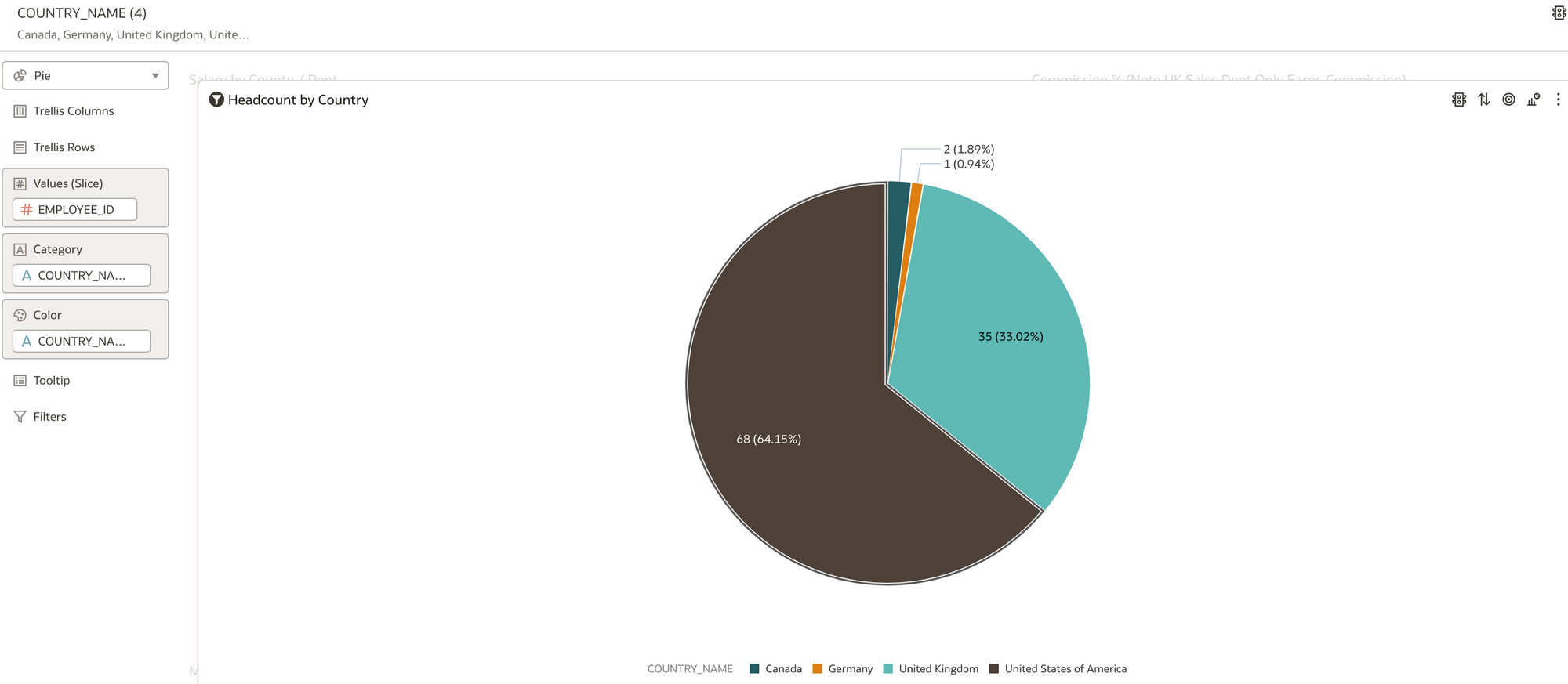 Pie Vis. Headcount by County Value and %
Pie Vis. Headcount by County Value and %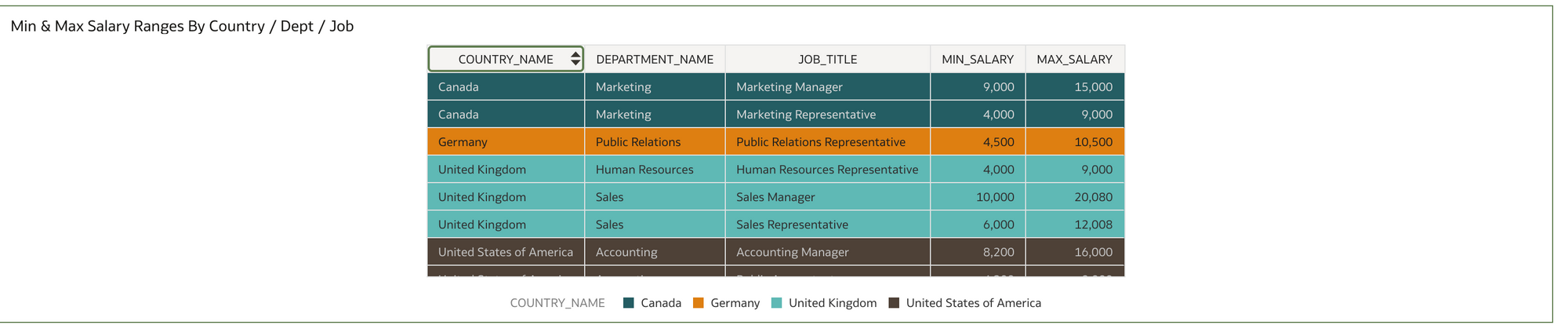 Table Vis. Min / Max salary ranges by dept and Job Title.
Table Vis. Min / Max salary ranges by dept and Job Title.I put a country filter on all the reports in the filter section of DV so I could limit to one or more countries.
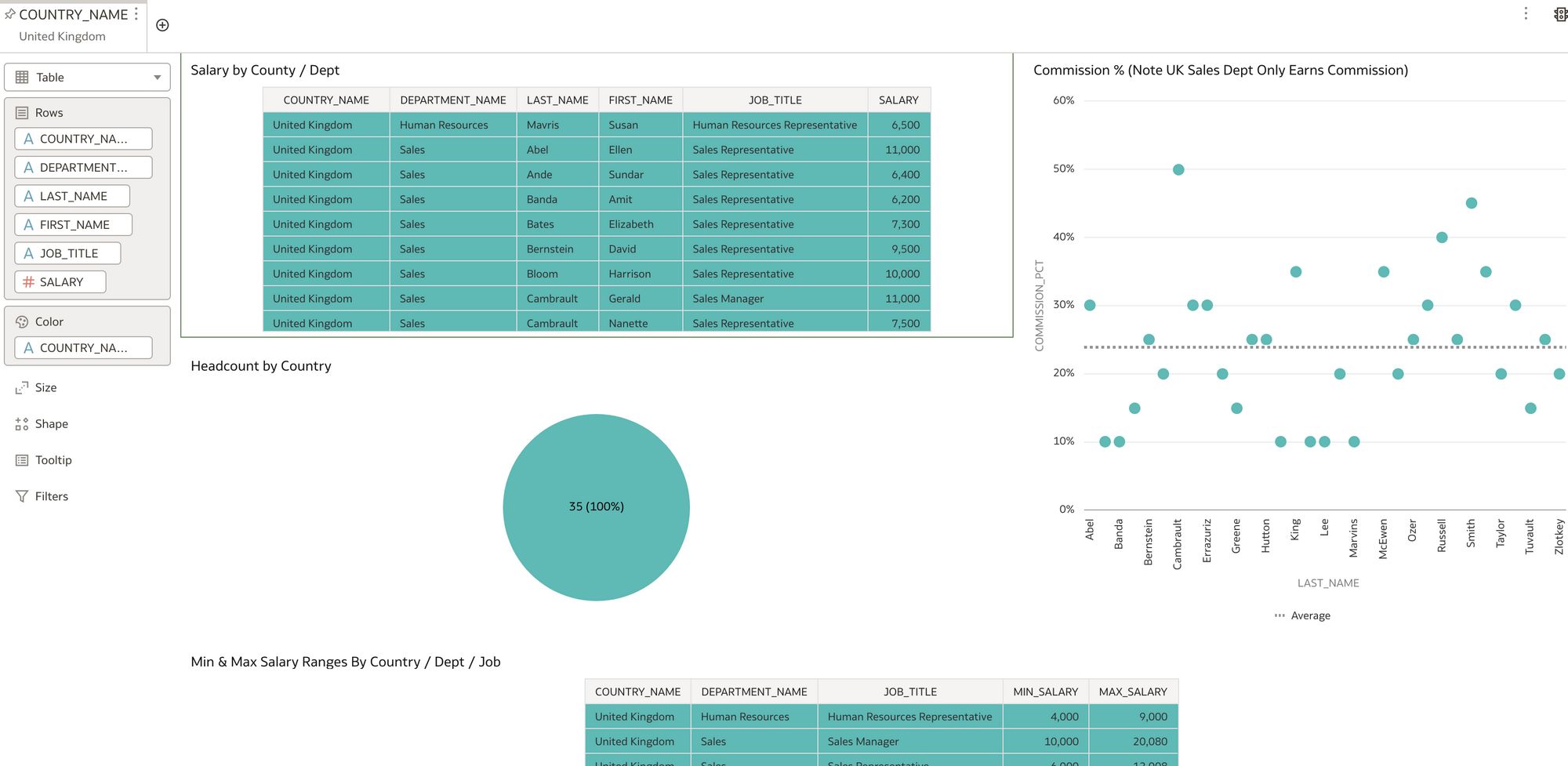 DV Filter Vis. Filtered on United Kingdom
DV Filter Vis. Filtered on United KingdomI found it fairly intuitive to use DV to write basic reports, however, there is a lot of functionality in DV that I can't even begin to cover here. So here is the sales pitch! Rittman Mead do a great course on DV https://www.rittmanmead.com/oracle-analytics-frontend/ :)
I also quickly had a look at the same HR dataset in OAS using the classic interface and felt very at home as a long time OBIEE user!
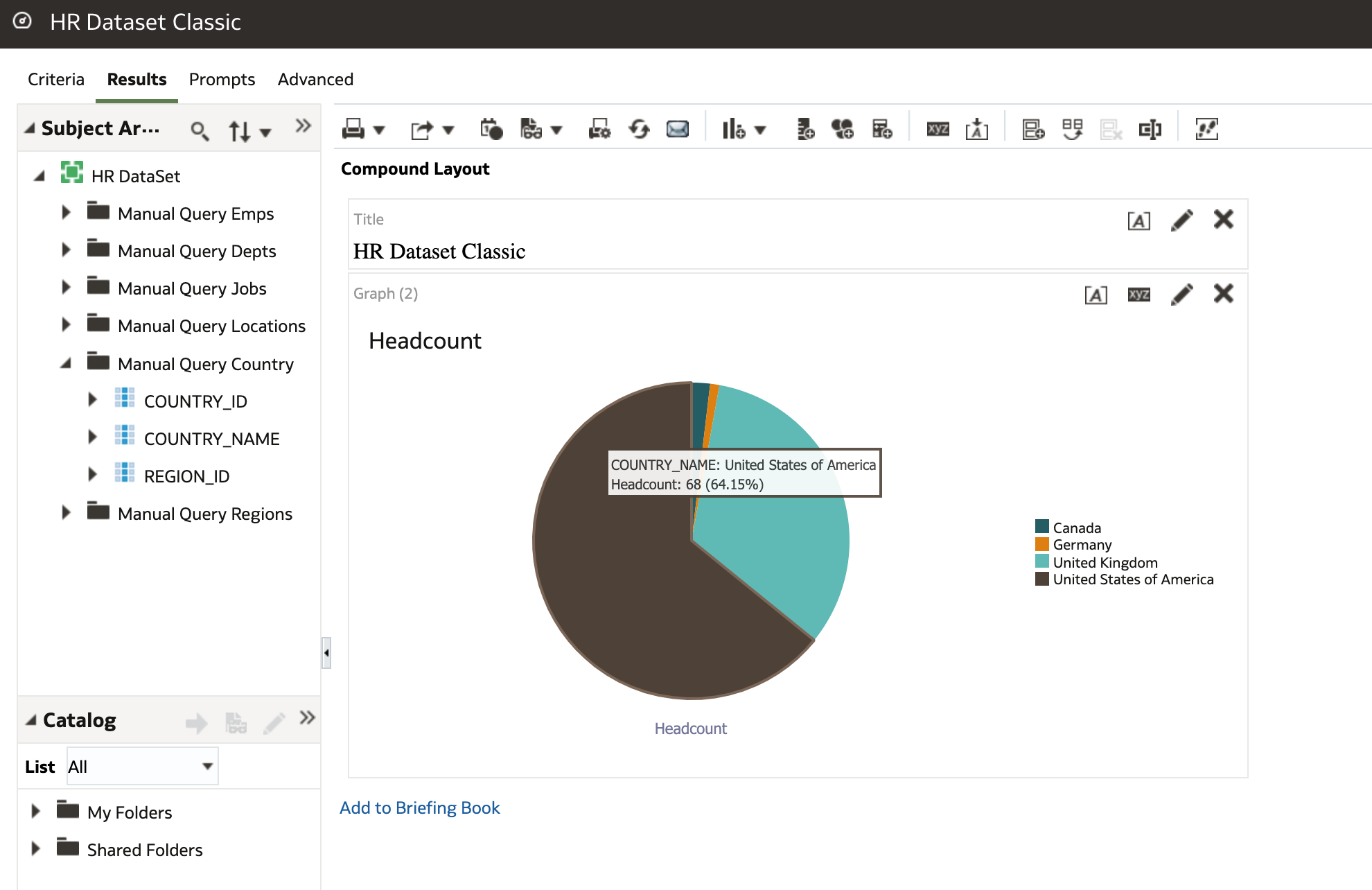 OAS Classic Report writing Interface
OAS Classic Report writing InterfaceIn Conclusion
With a little bit of effort, I created a working local OAS system locally on Docker desktop. I was able to connect OAS to an Oracle database. I created an OAS dataset against the HR database schema and wrote some basic DV reports using the dataset. At step 4 (above) I could see the HR team getting involved and assisting with or creating the dataset within OAS themselves and taking it from that point into DV or OAS Classic and creating the reports. Often in the HR team certain individuals have or want to learn SQL skills and the push is certainly in the direction of HR and payroll taking ownership of the data themselves. I used a very basic HR dataset however the principles for creating more data sets with more complex requirements and data would be the same.
What's next?
In my next blog I am going t0 show how I used the OAS repository (RPD) to model the same Oracle HR sample data and present it to the user as a Local Subject Area for writing HR reports against using DV. If you currently use OBIEE this could interest you as you can replicate your current subject areas in OAS and rewrite the reports in DV or keep them in the OAS classic look and feel on a dashboard. So you get the best of both worlds with OAS! DV and the OAS classic interface.
Introducing Rittman Mead Lineage Tool
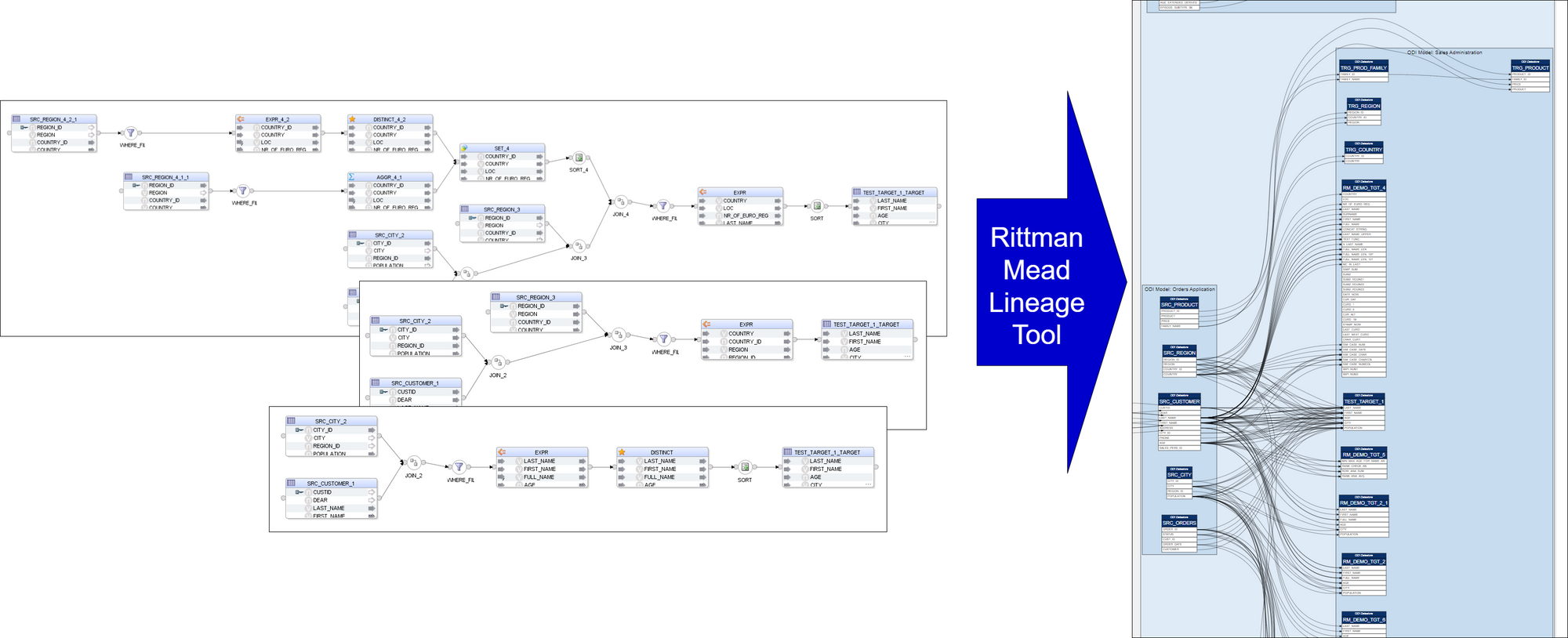
Rittman Mead Lineage Tool analyses ODI Mappings and produces neat visualisations of source-to-target mappings. The Lineage Tool is quick to set up and easy to run.
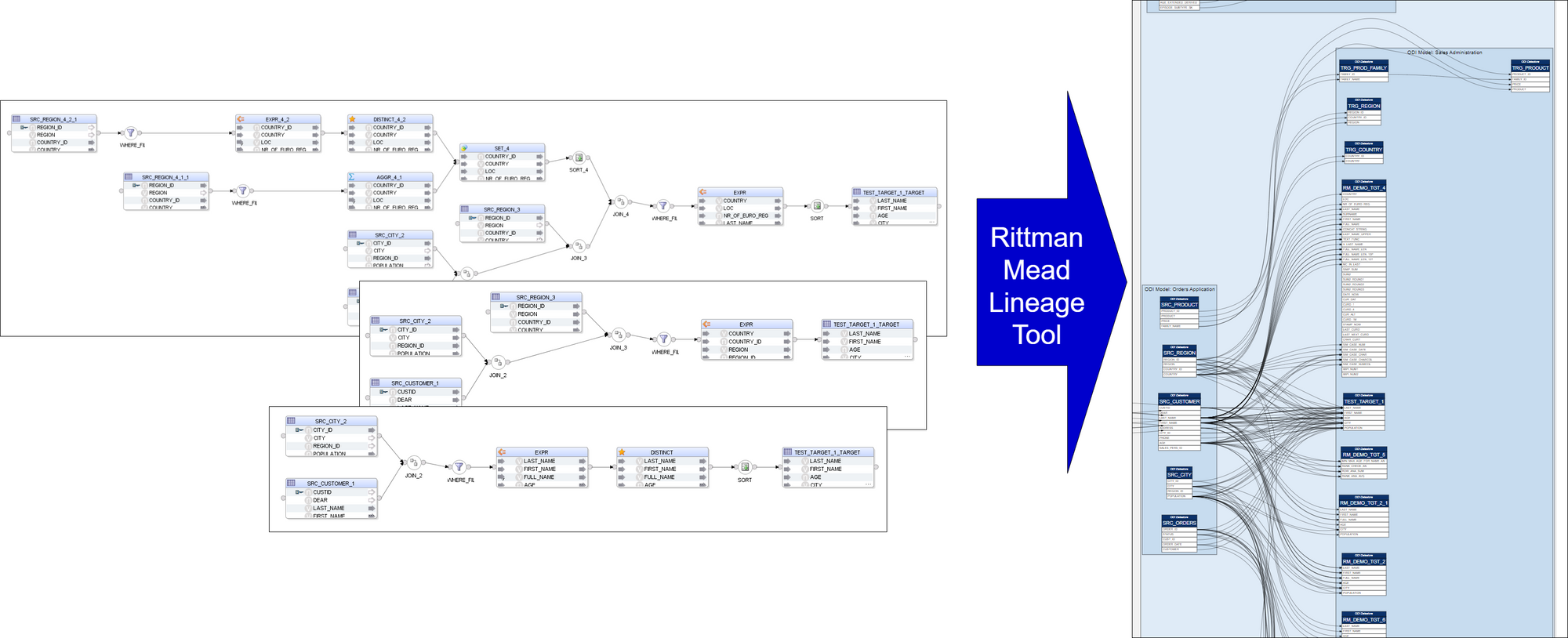 Rittman Mead Lineage Tool: from ODI Mappings to Mapping Lineage Visualisation
Rittman Mead Lineage Tool: from ODI Mappings to Mapping Lineage VisualisationThe Lineage Tool can be used to reverse-engineer legacy ELT logic as the first step in a migration project. It can be a useful tool to track the progress of ongoing ODI development by scheduling it to be run on a daily basis. The tool can be useful for ODI content documentation - the output it produces is a set of static, cross-navigable SVG files that can be opened and navigated in a web browser.
Running the Lineage ToolThe Lineage Tool connects to an ODI Work Repository via the ODI Java SDK. This means the tool will connect to the ODI repository in the same way ODI Studio does. (The Tool has no dependency on the ODI Studio.)
The Tool scans through ODI Repository Projects and Folders, looking for Mappings. For each Mapping it traces all Attributes (columns) in Target Datastores (tables) to their Source Datastores and Attributes.
 Extracting ODI metadata...
Extracting ODI metadata...An intermediate result of the analysis is metadata of columns and mappings between them - similar to a data dictionary - that is written into the Lineage Tool's metadata schema. This output is much richer in data than the visualisations ultimately produced, therefore can be used for ad-hoc analysis of the lineage.
 ...and generating Lineage Visualisations.
...and generating Lineage Visualisations.Based on the produced lineage metadata, the Lineage Tool generates visualisations. The visualisations are generated as SVG documents - vector graphics files that are written in format similar to HTML and support some of the functionality that an HTML file does: hyperlinks, HTML tables and HTML-like content formatting. The SVG documents are static (no Javascript), they are cross-navigable and support drill-down.
Exploring the LineageLineage explorations starts from a Landing page that gives a summary of the Lineage content.
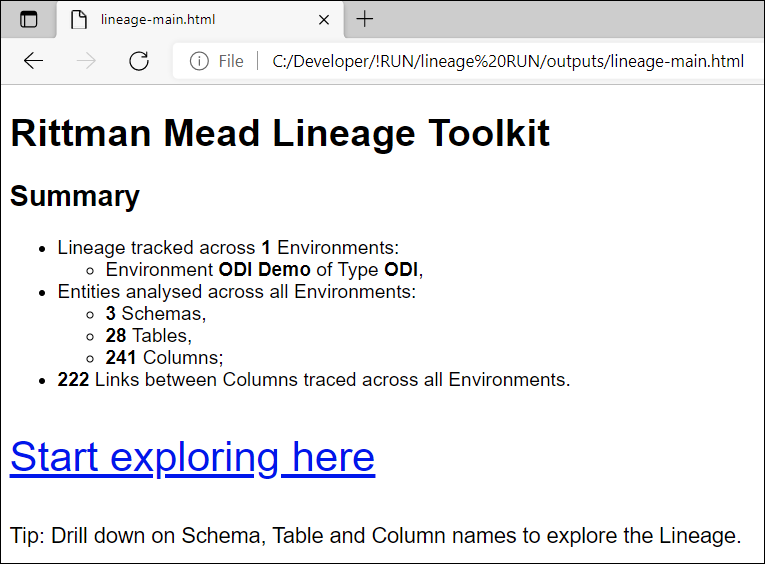
Lineage content is offered at 4 levels of granularity: Column, Table, Schema and Project.
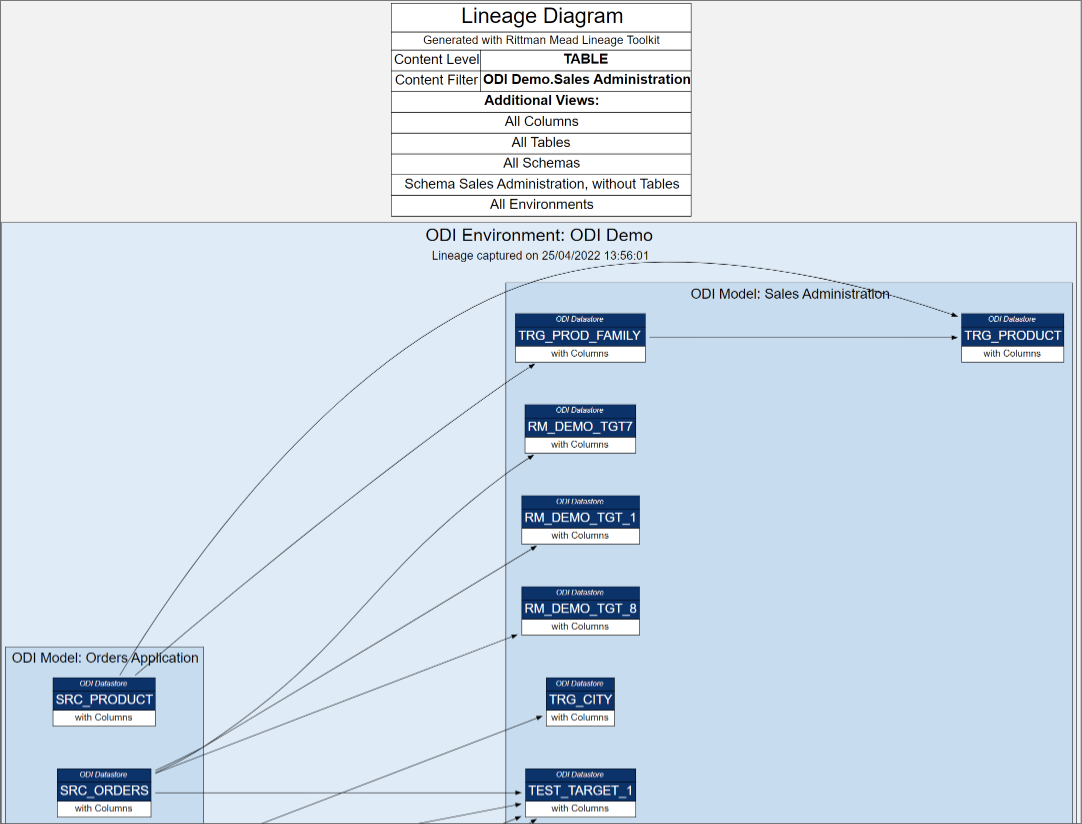 Exploring Lineage at Table level...
Exploring Lineage at Table level... ...and Column Level
...and Column LevelColumn and Table names, Schemas and Projects are navigable hyperlinks.
Clicking on a particular column gives us all source tables and columns as well as targets. We also get to see accompanying columns and their mappings - included for context but greyed out.
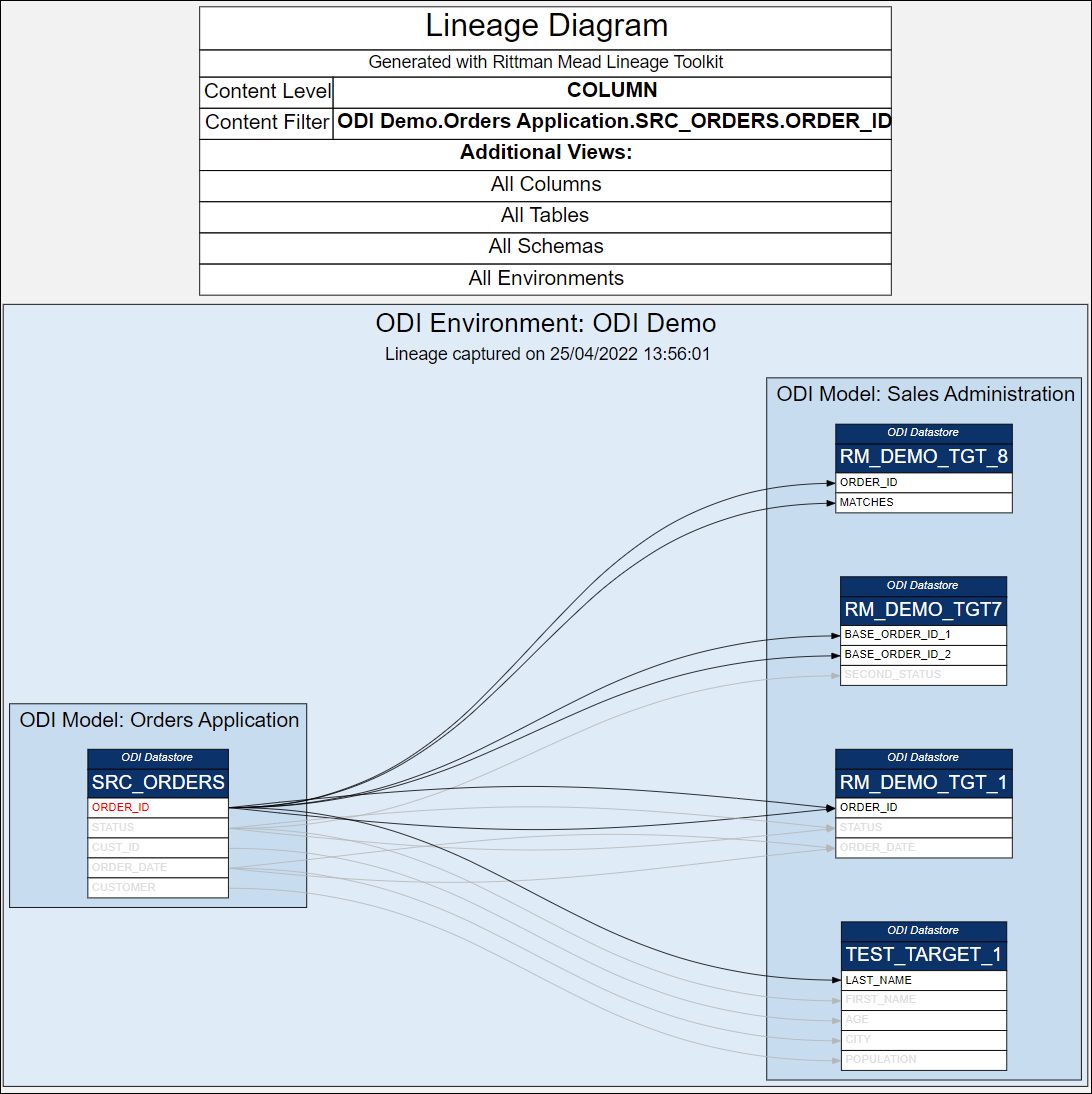 We can also explore a single Column.
We can also explore a single Column.A single column view can be useful for security audits - to trace sensitive data like Customer Address from OLTP source columns to Data Warehouse Dimension attributes.
Interested in finding out more about the Lineage Tool, contact us.
Oracle Analytics Server 2022 (6.4): The Best 15 New Features, Ranked
OAS 6.4 is finally live and provides a big set of enhancements that had been already available to OAC users. New features mostly affect the Data Visualization tool and involve the full process flow, from the data preparation to the data presentation, including visualizations, machine learning and administration improvements.
The focus of this post is on the best 15 new features of OAS 6.4 according to my personal opinion. I asked to my colleagues at Rittman Mead to rank them after a quick demonstration, so you know who to blame if the feature to hide loading messages is not at the top of the ladder!
If you are interested in a comprehensive list of new features and enhancements in OAS 6.4 please refer to What's New for Oracle Analytics Server.
15. Redwood theme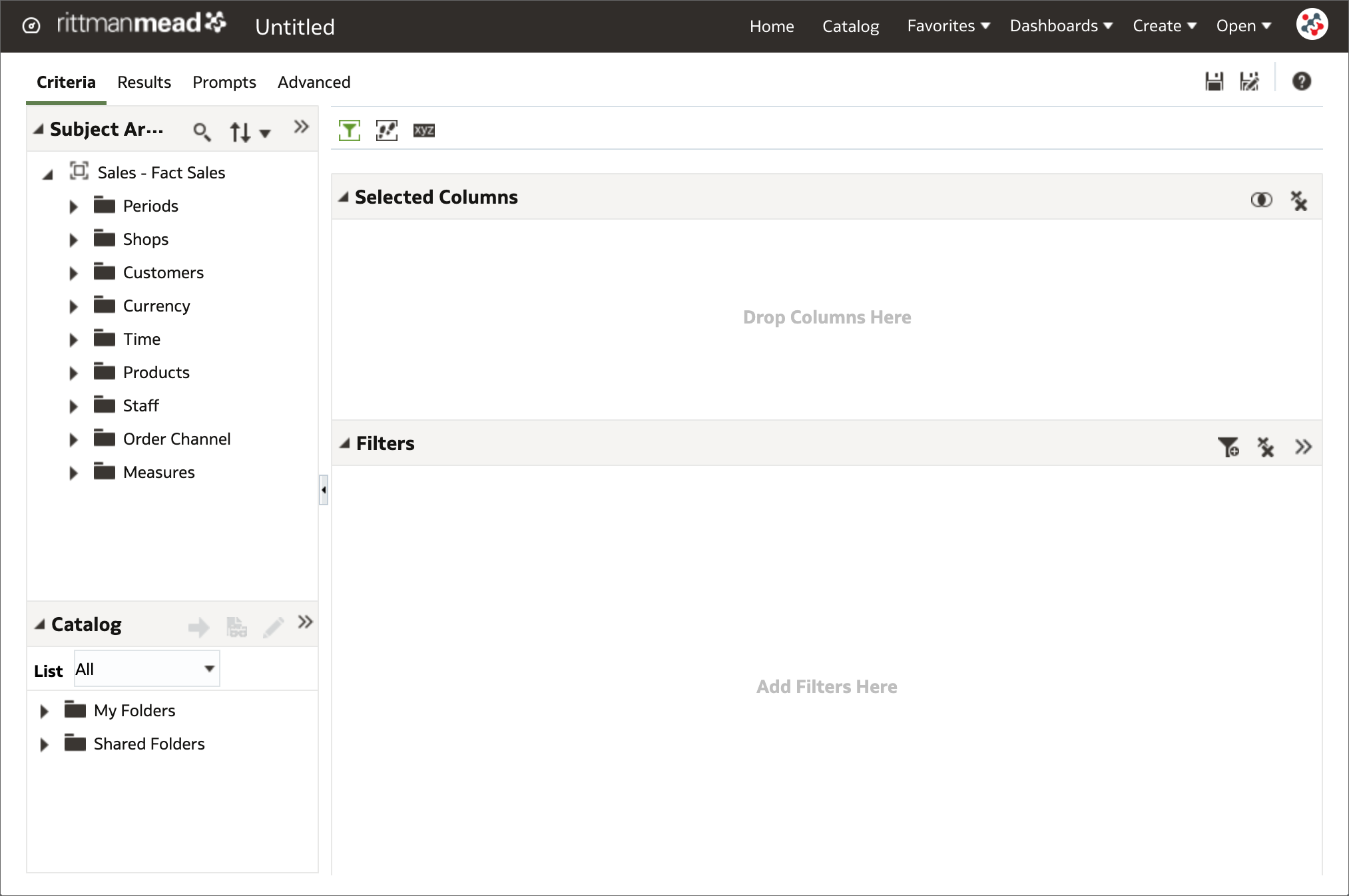 The Analysis Editor with the Redwood theme
The Analysis Editor with the Redwood themeOAS 6.4 includes components of Redwood - Oracle's new user experience design language. With a consistent look and feel across Analytics, Publisher and Data Visualization tools, the new default theme improves the user experience through a better handling of white space, a softer color palette, and new fonts.
14. Hide loading messages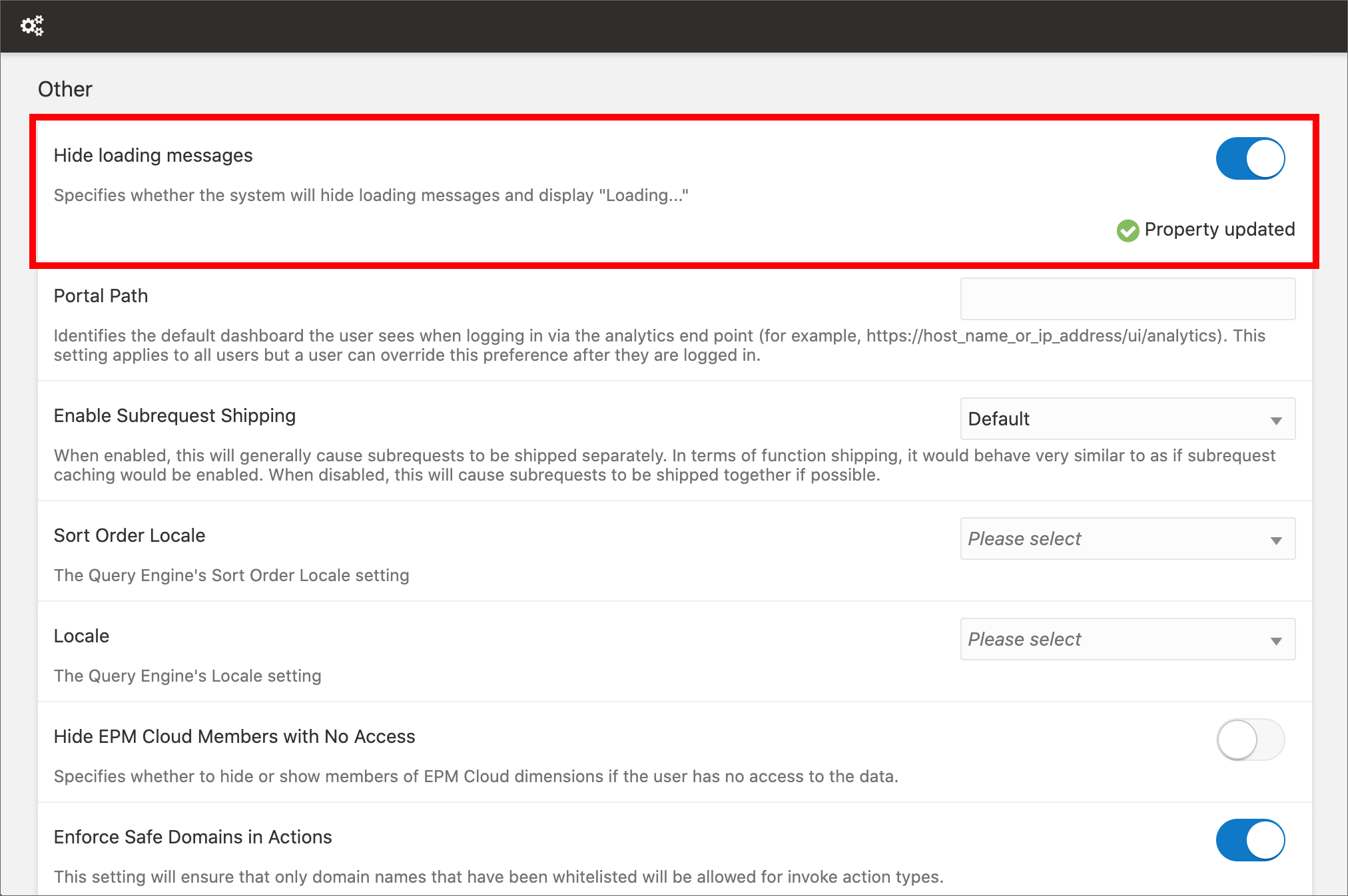 The new Hide loading messages setting
The new Hide loading messages settingFunny random quotes are displayed in Data Visualization during loading since it has been released, and since then people are asking for a way to disable or customize them. These messages can be fun for the first 2 seconds, but when they are displayed over and over if loading takes longer... I feel like the application is fooling me!
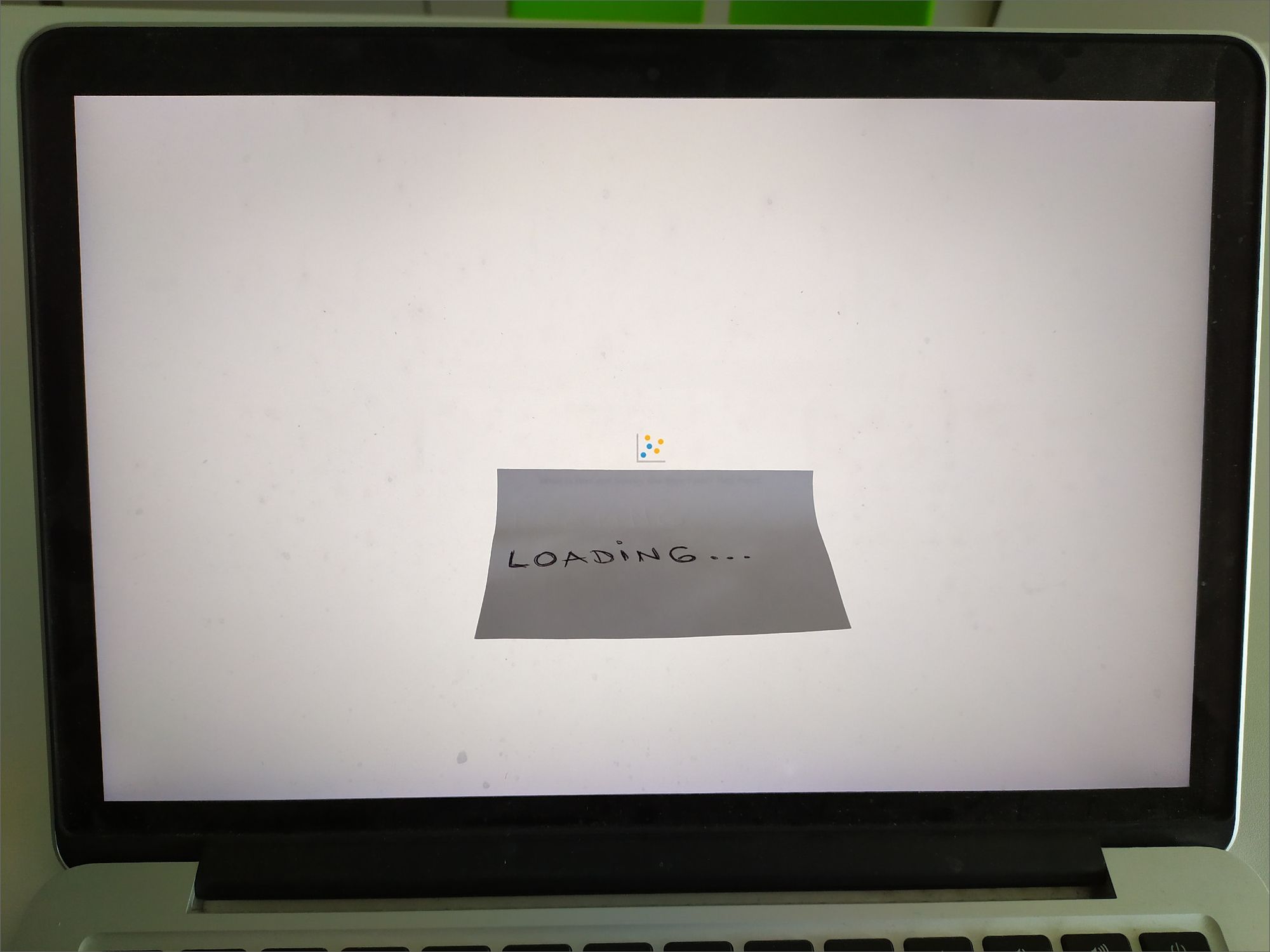 My workaround to hide loading messages in OAS 5.9
My workaround to hide loading messages in OAS 5.9I'm really happy to announce that I can finally crumple my loyal sticky note (see the picture above) because quotes can be replaced with a generic "Loading..." message in OAS 6.4. This can be done by switching on the Hide loading messages option in the System Settings section of Data Visualization Console, and restarting the Presentation Server.
13. Improved Home page search The new advanced search commands
The new advanced search commandsThe search bar in the Home page can be used to search for content and generate on-the-fly visualizations based on the chosen keywords. This was already one of my favourite features and it has been further improved in OAS 6.4: advanced search commands can be used to tailor search results for exact matches, multi-term matches, and field-level matches. When the list of accessible datasets is huge, these commands result particularly useful to quickly locate datasets created by a specific user or with a particular name. Unfortunately, the advanced search commands can be used only in the Home page search bar, and not in all other pages such as Data.
12. Support for Back button in browsersThe Back button in the browser can be pressed to navigate within the OAS 6.4 interface such as between editors and the Home page. Unfortunately, this cannot be used it in Analytics (Classic) and Publisher editors to undo an action.
11. View and export membership data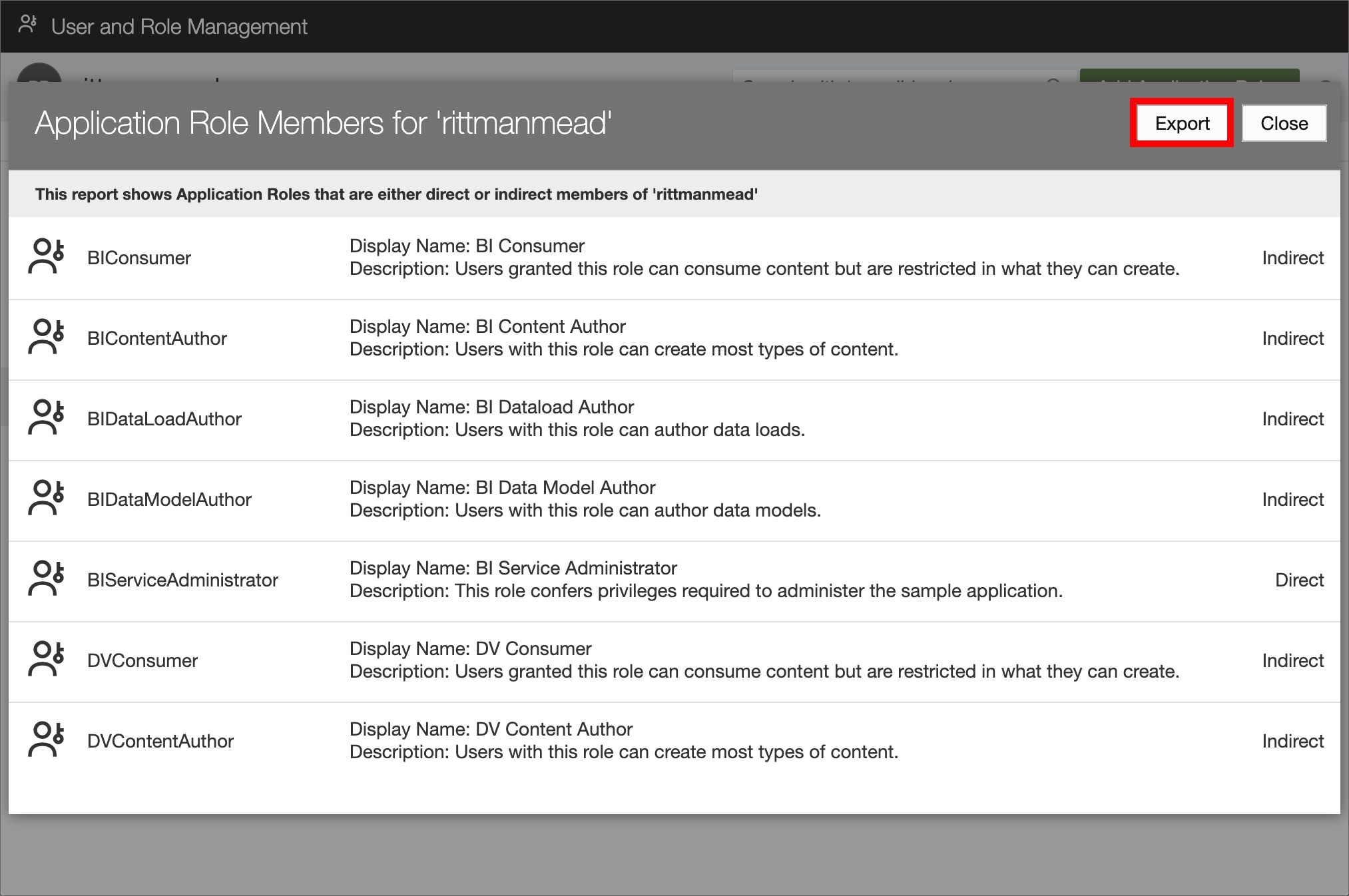 Exporting membership data in OAS 6.4
Exporting membership data in OAS 6.4Exporting membership data for auditing purposes and to find out exactly who has what access is a common task for any OAS administrator. To achieve this task I always used WLST with custom Python scripts, and I will probably continue with this approach in future. However, for users not familiar with WLST and Python, there is a new option in OAS 6.4 to download membership data for users, groups, and application roles to a CSV file in few clicks.
To view and export membership data for a user:
- Open the Users and Roles section in Data Visualization Console.
- Select the Users tab and select the name of the user whose membership details you want to see.
- Click on Application Roles (or Groups) under Direct Memberships.
- Click on the menu icon and select Show Indirect Memberships.
- Click on the Export button.
In a similar way membership data for groups and application roles can be viewed and exported.
10. Annotations on canvases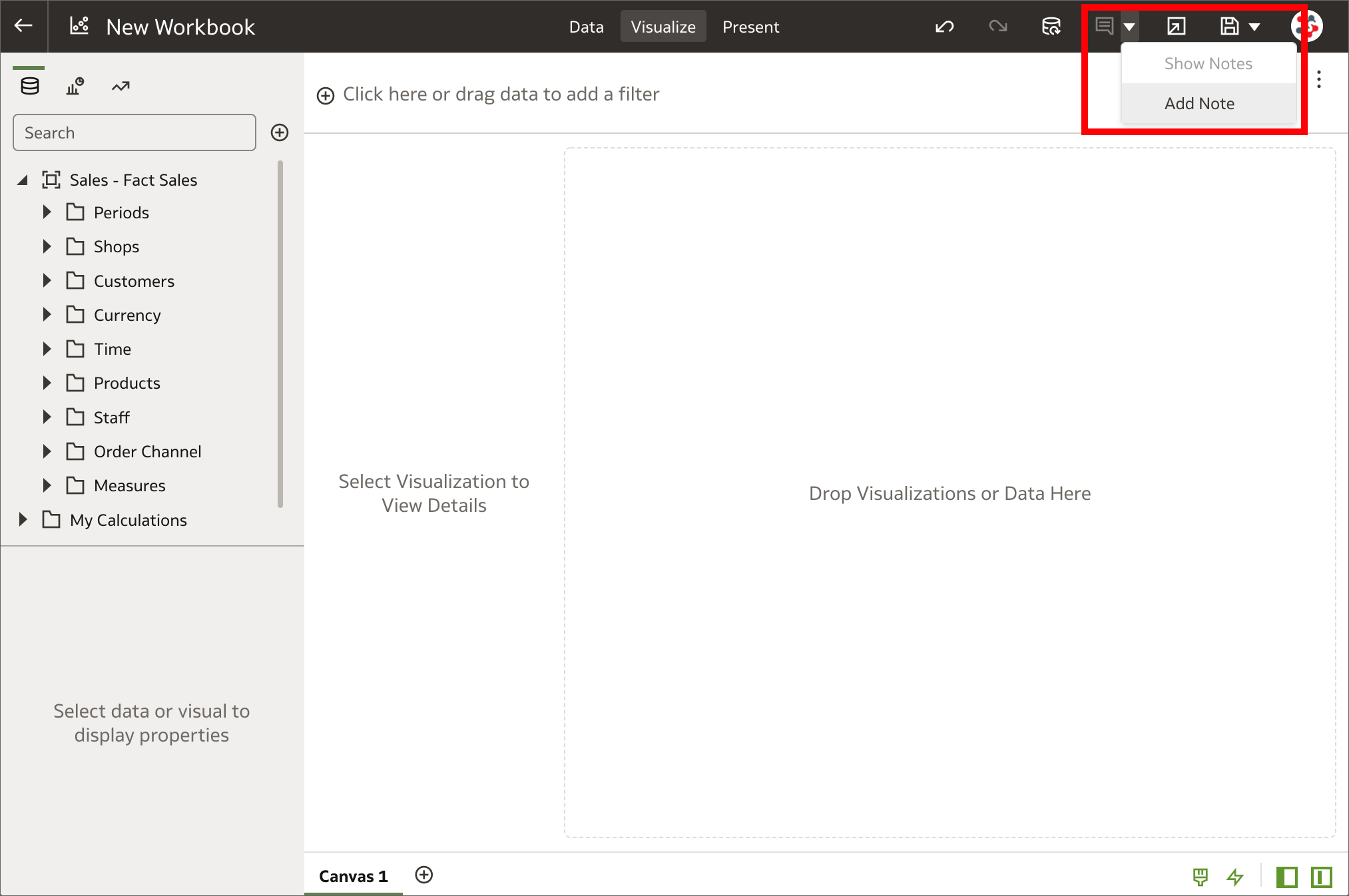 Adding notes in the Visualize tab
Adding notes in the Visualize tabNotes are a great way to emphasize or explain important information in visualizations, but I always found it limiting to be able to use them only in Data Visualization stories. In OAS 6.4 notes can be added to canvases in workbooks and tied to specific data points also in the Visualize tab. If you are wondering what a workbook is, it's just how projects are called in the new release!
9. Expression filters for entities in datasets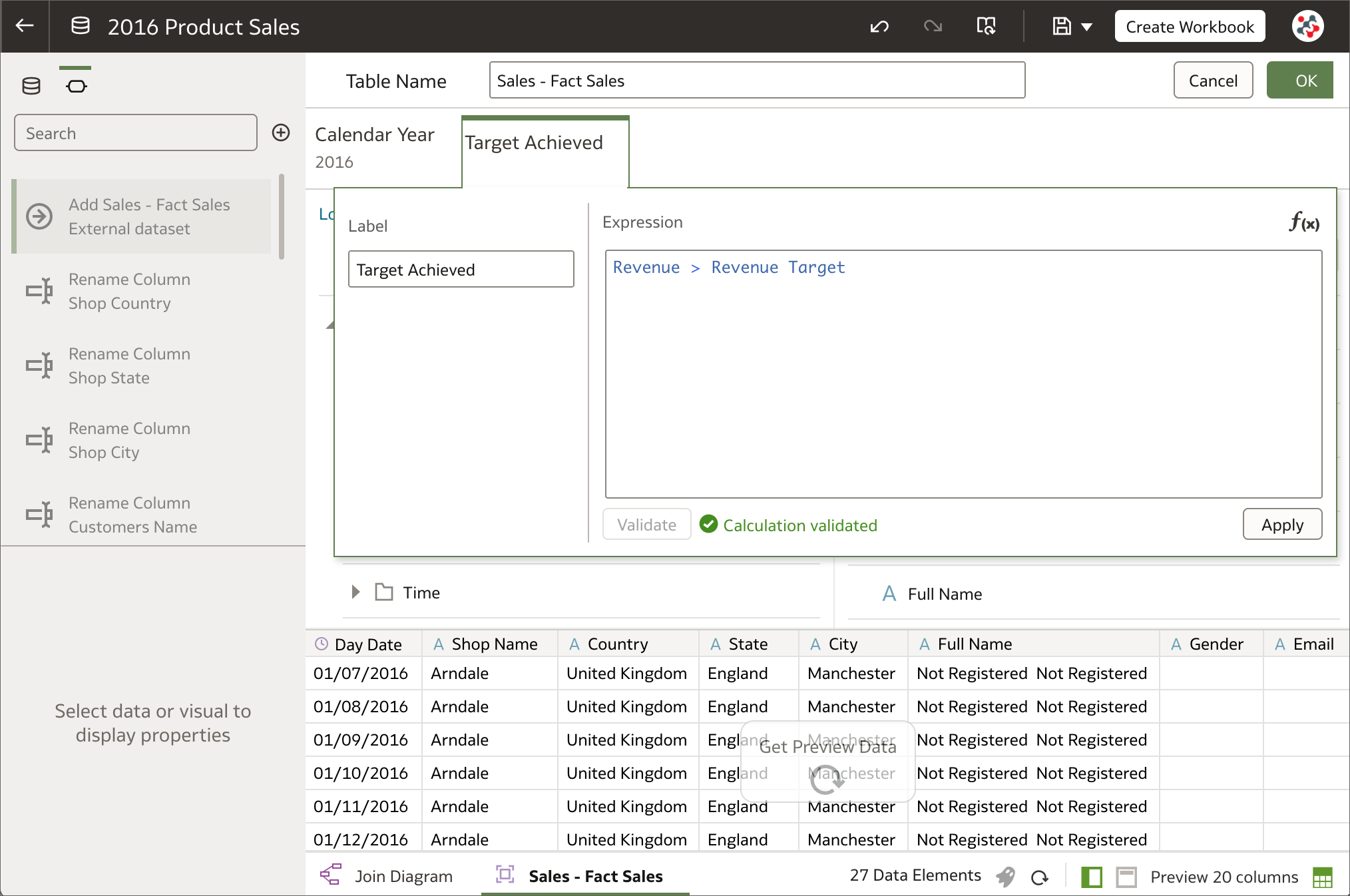 Filtering entities in datasets using expression filters
Filtering entities in datasets using expression filtersWhen a column is added to a dataset from a database connection or a subject area, all of the column values are included in most cases. Columns can be filtered so that the dataset contains only the rows needed, but it was not possible to filter on expressions in OAS 5.9. More complex filters are now supported by using expression filters. They must be Boolean (that is, they must evaluate to true or false) and can reference zero or more data elements.
8. Select multiple columns/visualizations for editing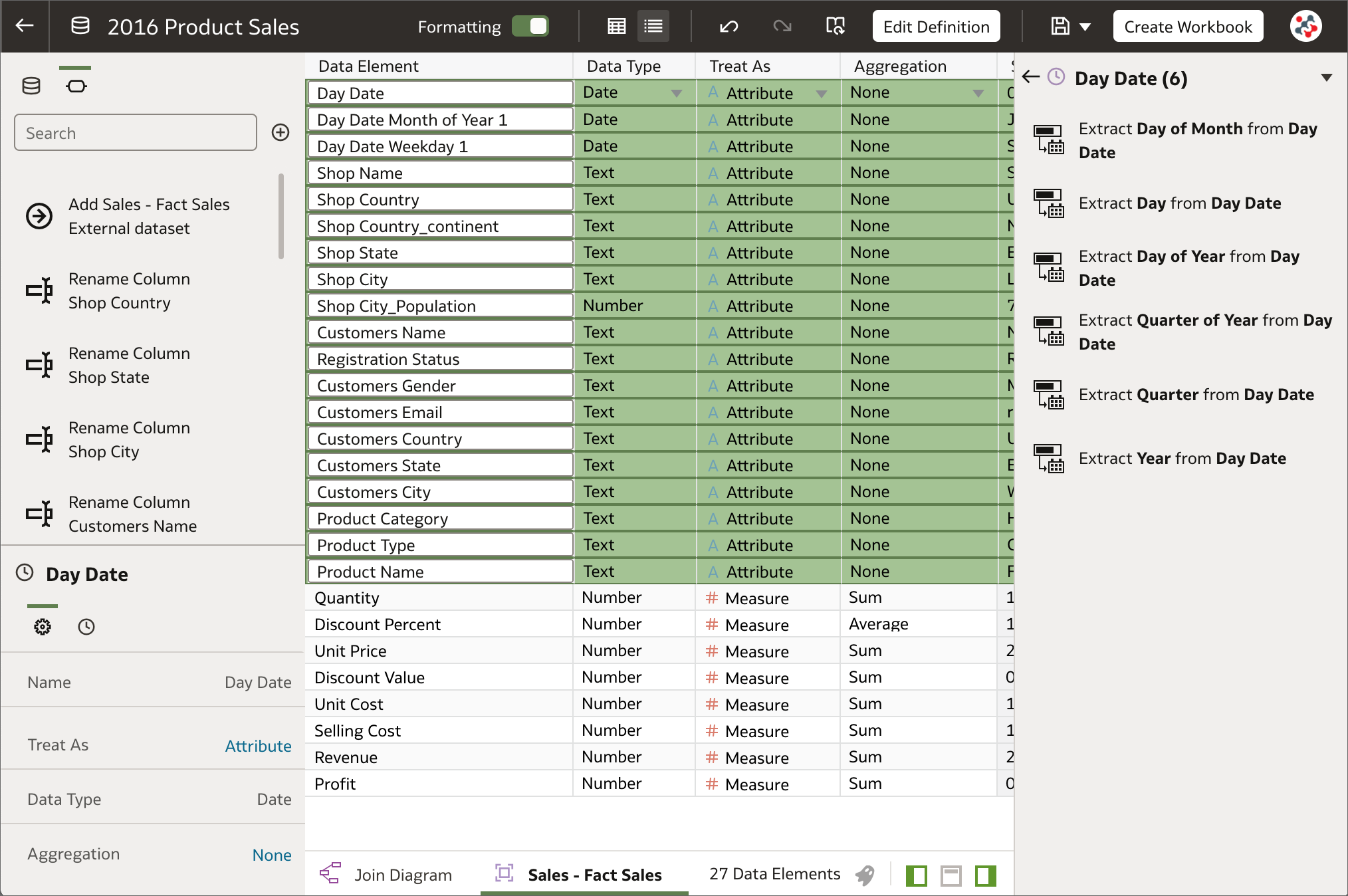 Selecting multiple columns for editing
Selecting multiple columns for editingIn the Metadata view of the Dataset Editor multiple columns can be selected to change settings (Data Type, Treat As, Aggregation and Hide) for more than one column at once. This is not yet possible in the Data view, properties of one column at a time can be configured. In a similar way, multiple visualizations can be selected on a workbook to easily change shared properties, copy and paste, and delete them. These two new features will surely allow users to save time when changing settings for multiple objects.
7. Automatic refresh of visualizations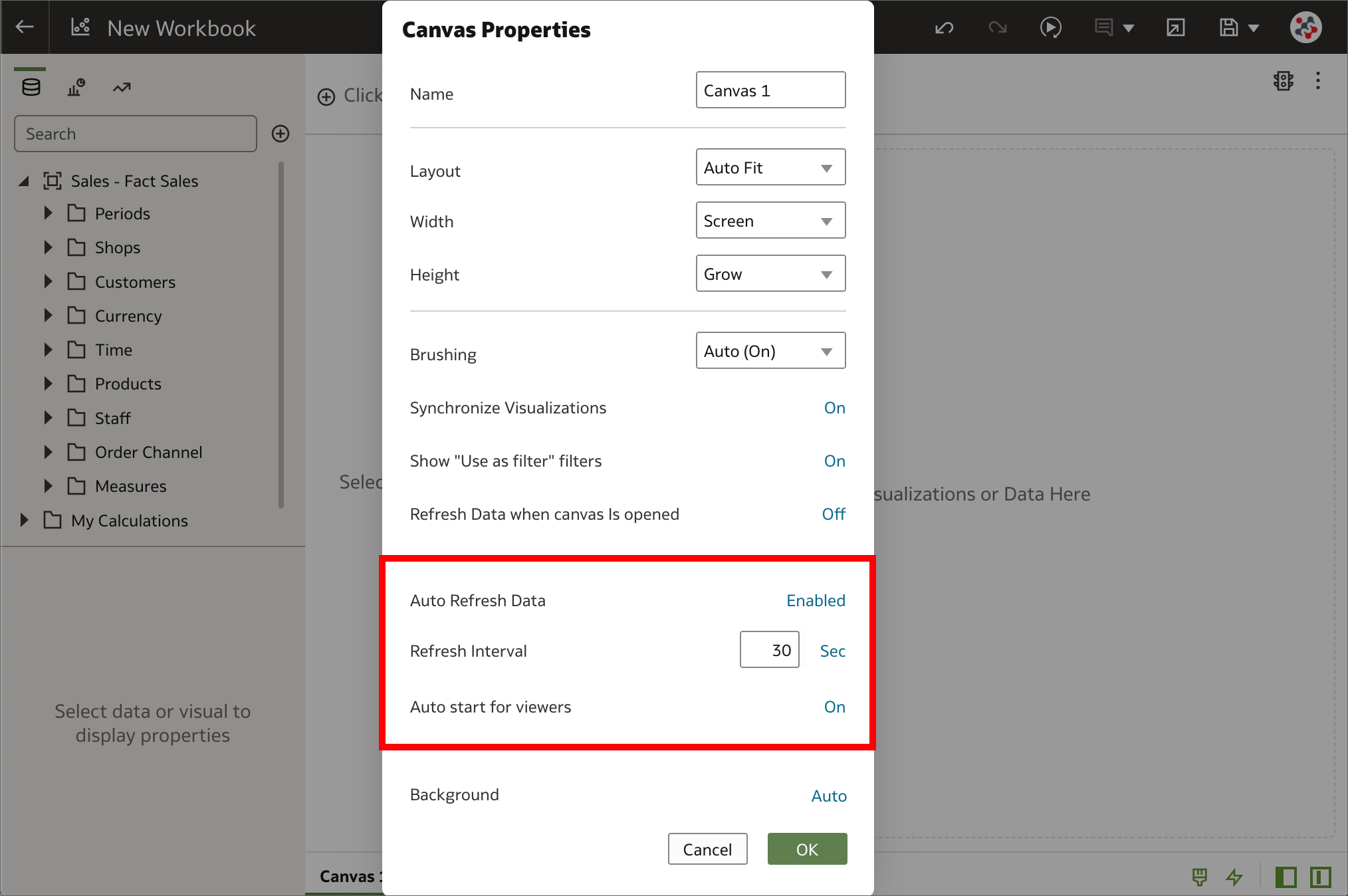 Automatic refresh of visualizations
Automatic refresh of visualizationsData in workbooks can now be automatically refreshed at a specified interval to ensure that the visualizations contain the most current data. It's sufficient to right-click on a canvas tab, select Canvas Properties and set Auto Refresh Data to Enabled to automatically refresh the data using a given Refresh Interval. Please note that this operation does NOT trigger a data cache reload. If a dataset table's access mode is set to Automatic Caching, then the table re-queries the cached data that could be stale.
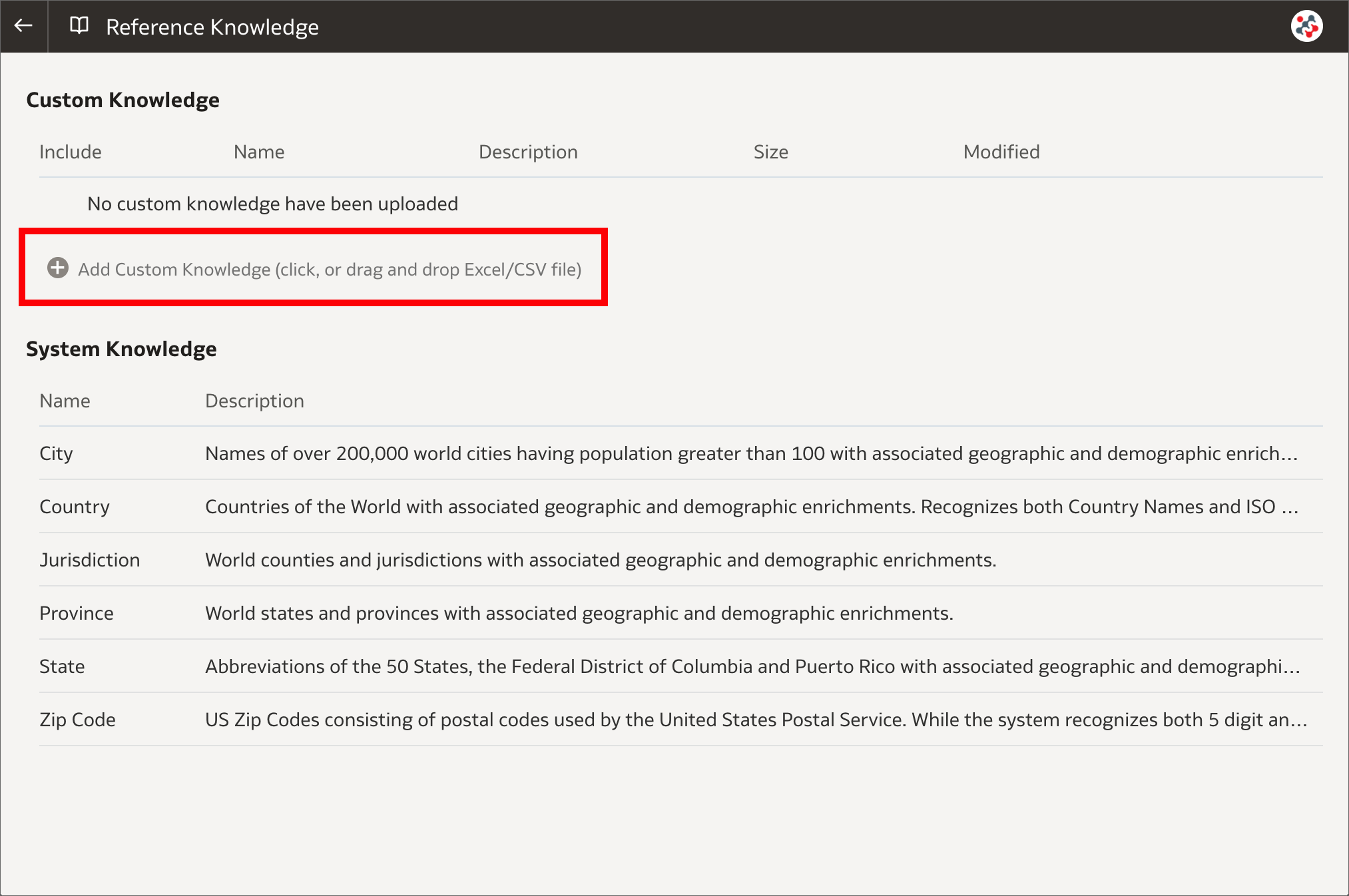 Adding custom knowledge
Adding custom knowledgeAfter creating a dataset, the dataset undergoes column-level profiling to produce a set of semantic recommendations to enrich the data. These recommendations are based on the system automatically detecting a specific semantic type (such as geographic locations or recurring patterns) during the profile step. In OAS 6.4 custom knowledge recommendations can be used to augment the system knowledge by identifying more business-specific semantic types and making more relevant and governed enrichment recommendations. System administrators can upload custom knowledge files using the new Reference Knowledge section in Data Visualization Console. Custom knowledge files must be in CSV or Microsoft Excel (XLSX) format, contain keys to profile the data in the first column, and enrichment values in the other columns.
5. Data quality insights Data quality insights
Data quality insightsOAS 6.4 automatically analyzes the quality of the data in the Dataset Editor, and provides a visual overview known as a quality insight in a tile above each column. Quality insights allow to explore data in real time using instant filtering, evaluate data and identify anomalies and outliers, replace or correct anomalies and outliers, and rename columns.
4. Developer Options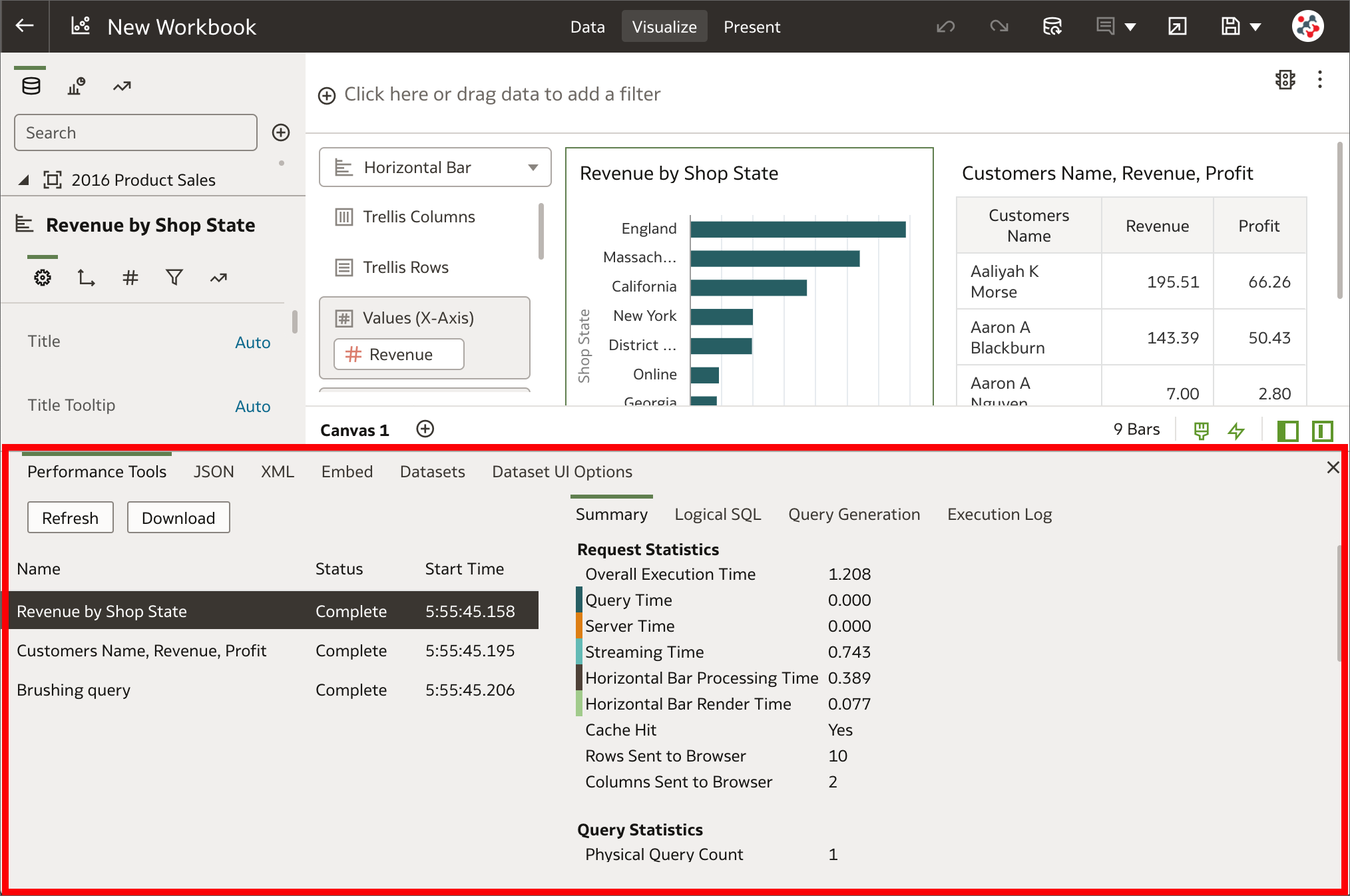 The Developer Options pane
The Developer Options paneIn Data Visualization, built-in developer options are now available to embed content in other applications and analyze statistics such as query time, server, and streaming time for visualizations in workbooks. Users with administrator or content author privileges can display developer options by appending &devtools=true to the URL of a workbook in the browser.
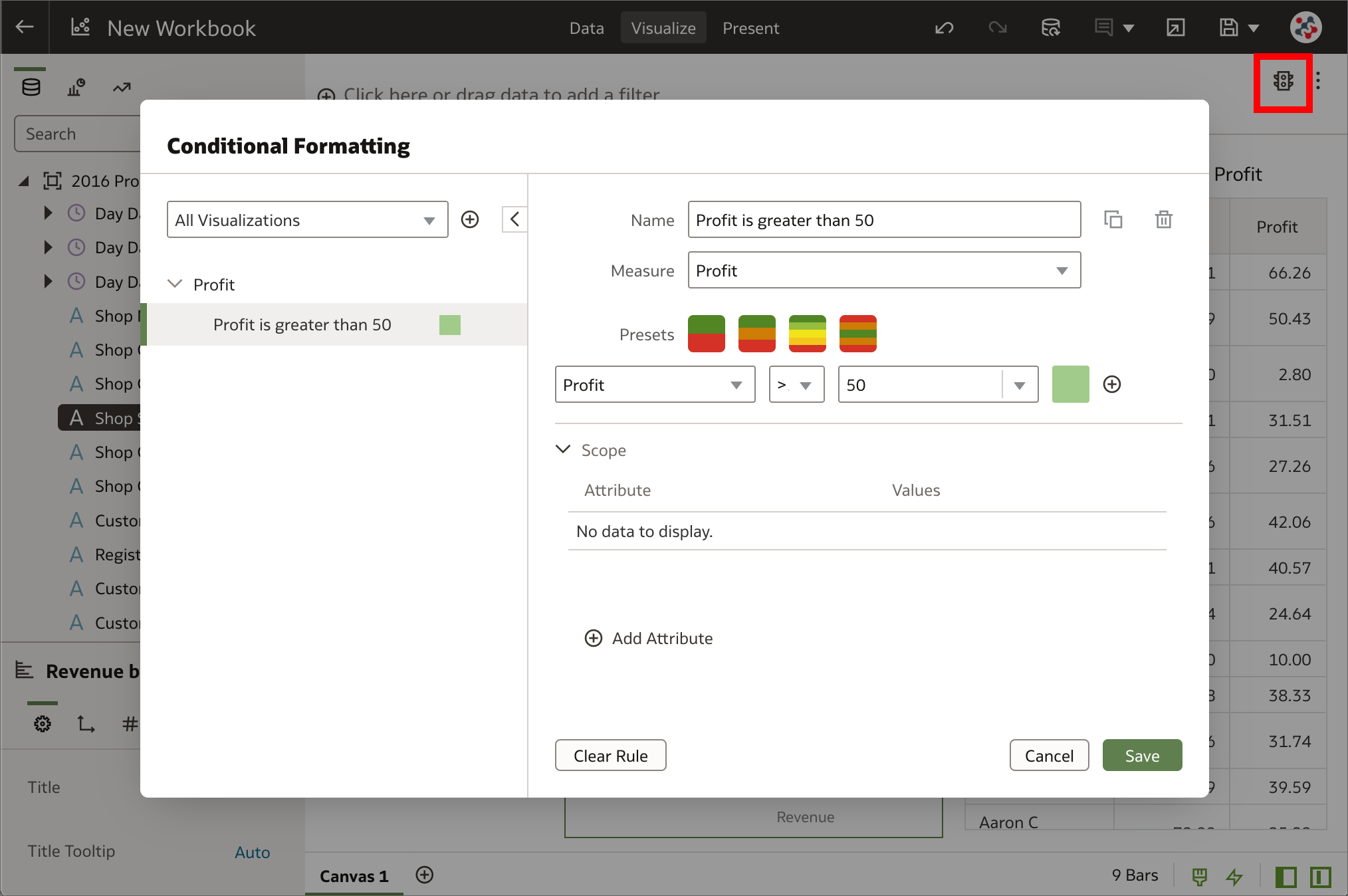 Conditional formatting is now available in Data Visualization
Conditional formatting is now available in Data VisualizationHow can conditional formatting be applied to workbooks in Data Visualization similar to the way it can be applied to analyses in Analytics (Classic)? This is frequently asked in Data Visualization training and the answer used to be that the feature was not available - a workaround was required to achieve something similar (e.g. by dragging a conditional expression to the color drop target and changing the color assignments as required). In OAS 6.4 it's now possible to highlight important events in data in a proper manner by clicking on the Manage Conditional Formatting Rules icon in the visualization toolbar.
2. Reload datasets on a schedule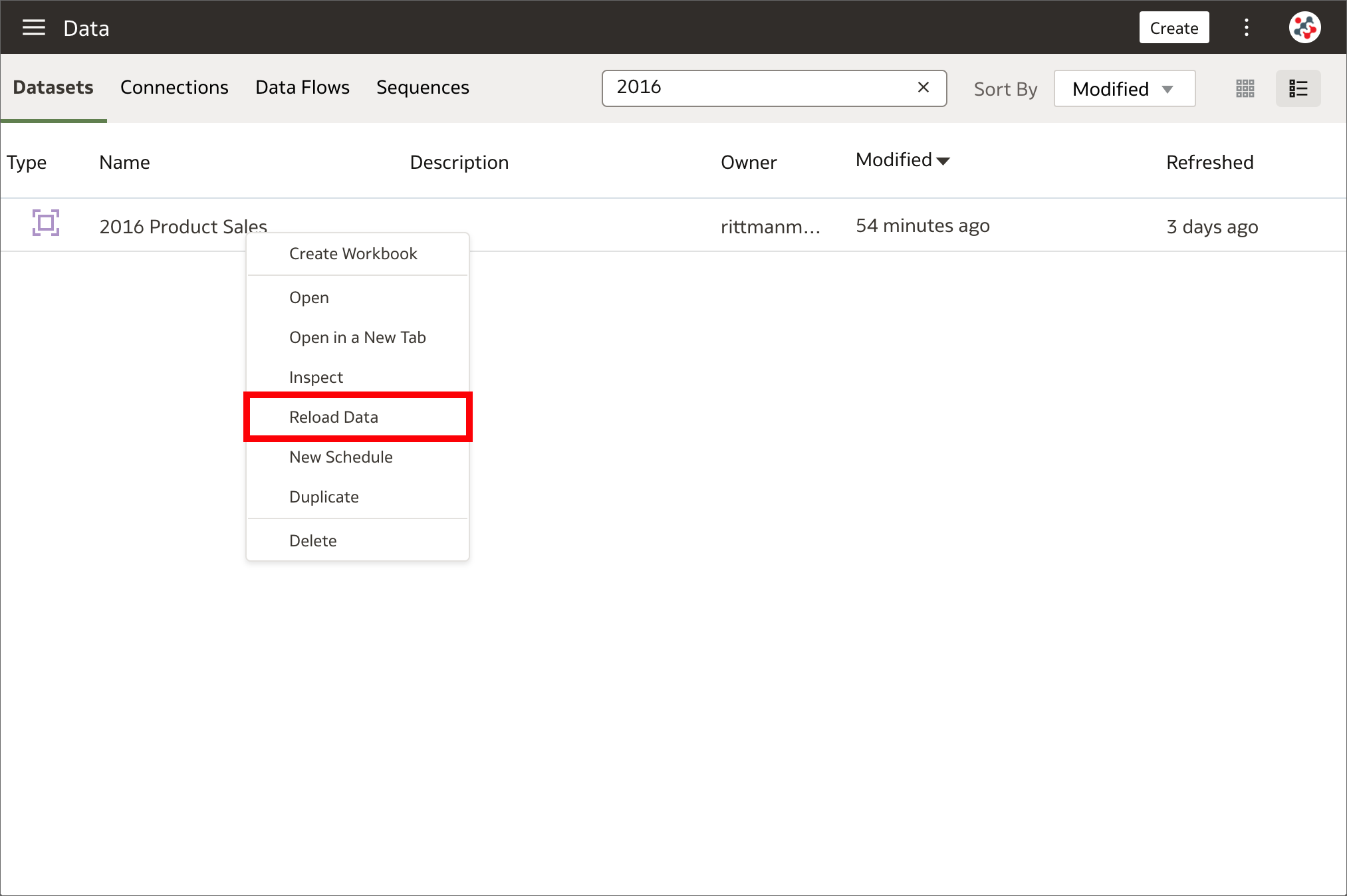 Datasets can be reloaded on a schedule
Datasets can be reloaded on a scheduleReloading datasets ensures that they contain current data. When a dataset is reloaded and it contains one or more table with the Data Access property set to Automatic Caching, the dataset's SQL statements are rerun and the current data is loaded into the cache to improve performance. This has always been a manual process in the past, but now it can be automated by creating a one-time or repeating schedule to reload a dataset's data into the cache. The New Schedule option has been added to the Actions Menu which appear by right-clicking on a dataset in the Data page. This option is NOT available for datasets that use only files or when data access for all tables is set to Live.
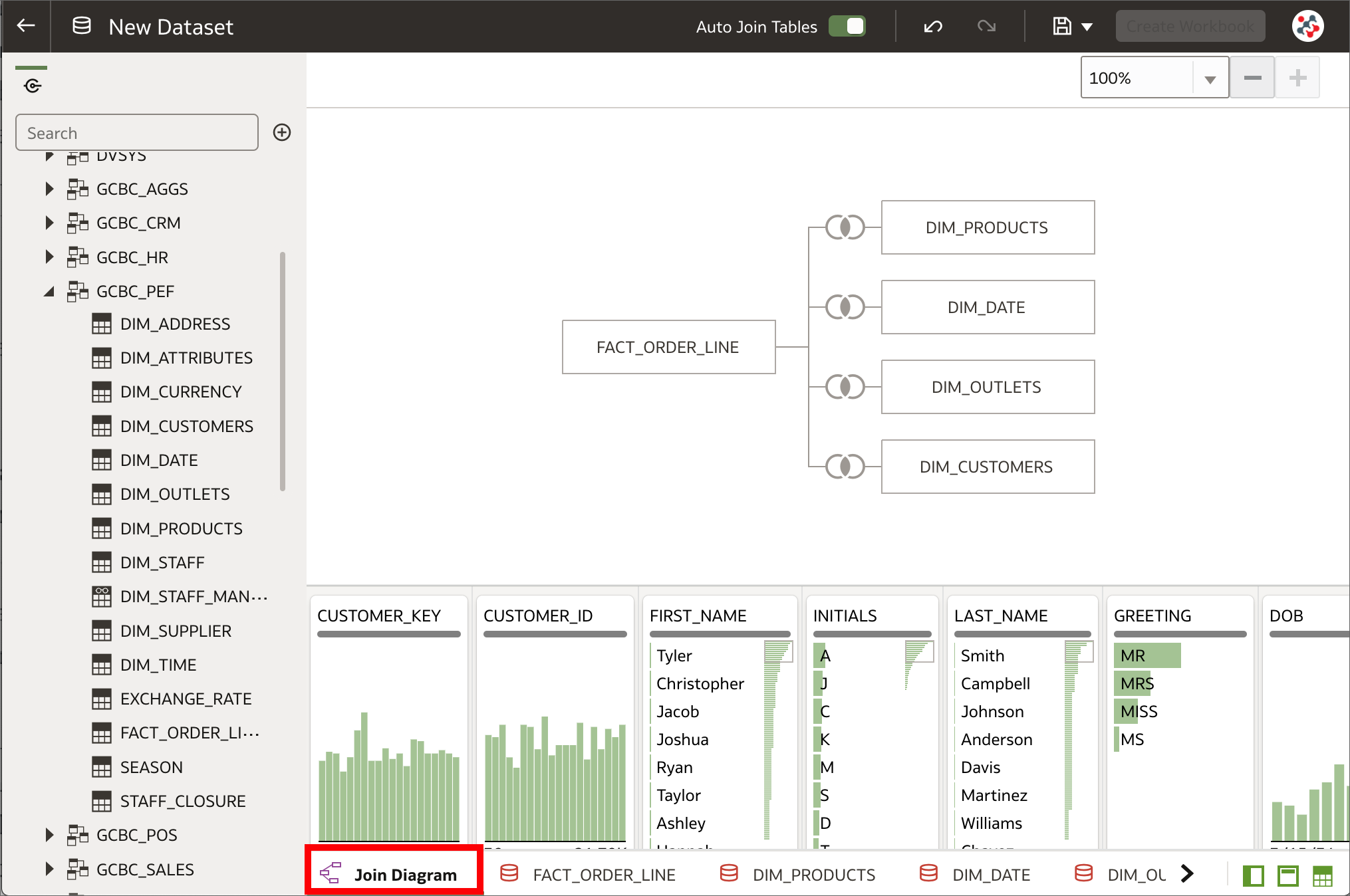 Datasets with multiple tables can now be created
Datasets with multiple tables can now be createdIn OAS 5.9 it was possible to create a dataset only with a single entity from a data source connection or a local subject area. This could have been a set of columns from a single table, when the Select Columns option was selected, or a more complex query with joins and native functions, when the Enter SQL option was used instead.
As downsides:
- Users without any SQL knowledge were not able to join tables in a dataset, or they had to run a data flow to join multiple datasets to achieve a similar result.
- It was always necessary to retrieve all columns from all tables in a complex query, even when only one was included in a visualization, and this resulted in potential performance issues.
OAS 6.4 allows to perform self-service data modeling with datasets by adding multiple tables to a dataset from one or more relational data source connections or local subject areas. Not all the supported data sources can be used to create datasets with multiple tables. Please refer to Data Sources Available for Use in Datasets Containing Multiple Tables for a comprehensive list.
The Dataset Editor contains a new Join Diagram pane which displays all of the tables and joins in the dataset. When tables are dragged and dropped to the Join Diagram, joins are automatically added if they are already defined in the data source and column name matches are found between the tables. It's possible to prevent this default behaviour and define joins manually by switching off the Auto Join Tables toggle button in the Dataset Editor.
When creating datasets with multiple tables, Oracle recommends to:
- Add to the dataset the most detailed table first (a fact table when data are dimensionally modeled) and then all remaining tables that provide context for the analysis.
- Create a dataset for each star schema and use data blending to analyze data based on two star schemas.
OAS 6.4 treats datasets with multiple tables as data models in that only the tables needed to satisfy a visualization are used in the query. This is surely the best new feature of this release and represents a valid alternative to model data in the Metadata Repository (RPD) for users interested only in the Data Visualization tool.
ConclusionOAS 6.4 includes an incredible amount of new features and the Data Visualization tool has been significantly improved. The support to datasets with multiple tables alone is worth the upgrade as it allows to define complex and structured datasets without impacting performance.
If you are looking into OAS 6.4 and want to find out more, please do get in touch or DM us on Twitter @rittmanmead. Rittman Mead can help you with a product demo, training and assist within the upgrade process.
Unify 10.0.49

A new release of Unify is available, 10.0.49. This release includes support for Tableau 2021.4.
- Unify 10.0.49 Windows Desktop x64
- Unify 10.0.49 Windows Desktop x86
- Unify 10.0.49 Server
- Unify 10.0.49 MacOS
Please contact us at unify@rittmanmead.com if you have any questions.
The role of Data Lakes or Staging Areas for Data Warehouse ETL
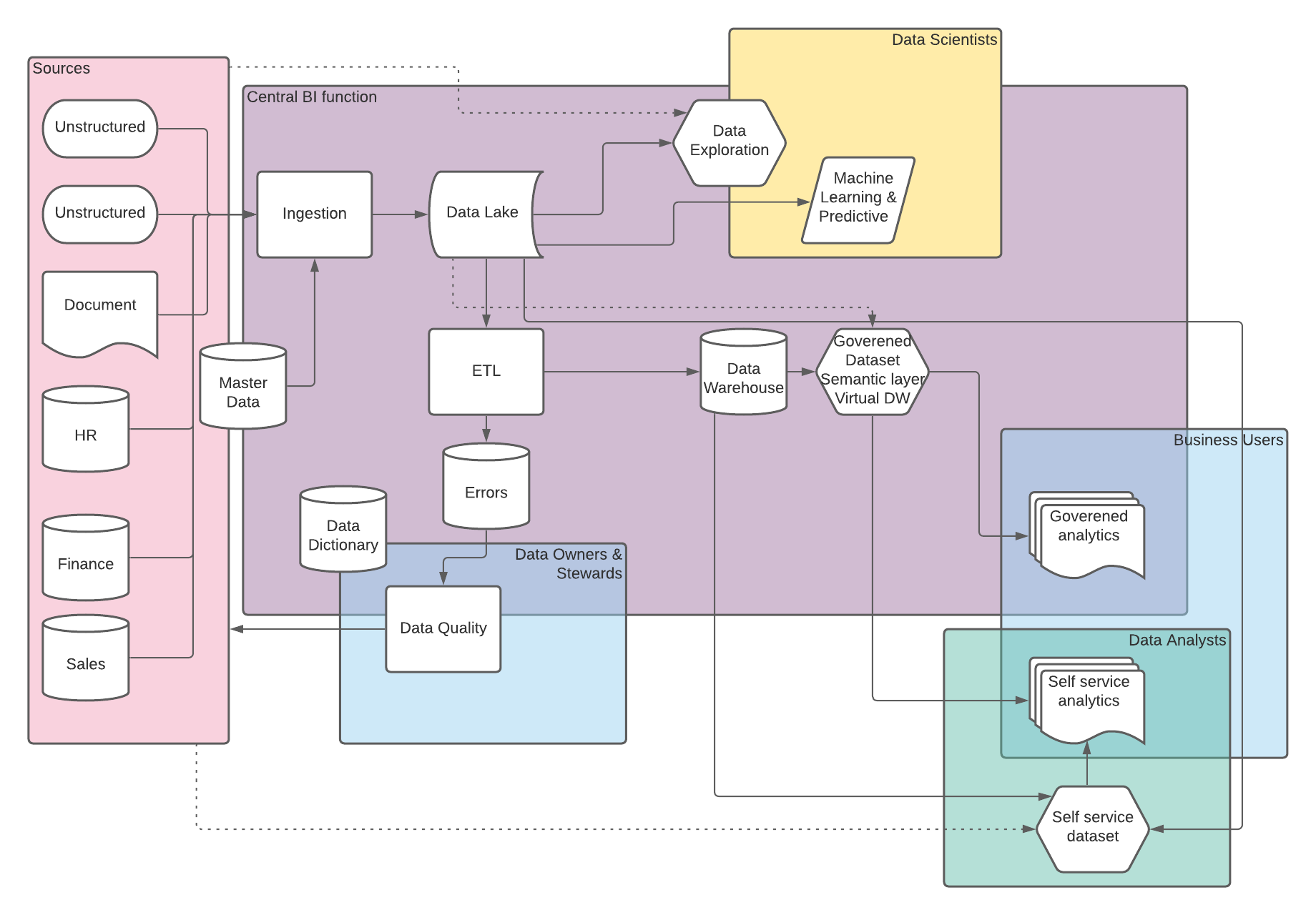
We were asked recently by a client, about the role of a staging area for ETL processes when loading a Data Warehouse, specifically they wanted to know if this was still required if using a Data Lake.
TLDR: Data Lakes and Staging areas could be interchangeable in terms of ETL processes, the key consideration is who else and what else will make use of the data within a Data Lake and do you have the right policies and procedures in place to ensure good data governance.
As with so many things people often see Data Lakes as a technology solution, but the reality is that its is a service. Data Lakes provide a method of surfacing data in it's raw/native form to a variety of users and down stream processes, these are intented to use relatively cheap storage and to help accelerate insights into business decisions. We see clients opting to implement Data Lakes on a variety of different technolgies which have various individual benifits, drawbacks and considerations, however the previaling trend in terms of operating an effective Data Lake and in terms of controlling cost is the need for careful goverance in terms of various aspects of data quality and secuirty including items such as data retention, and data dictionary.
A staging area for a Data Warehouse serves a single focused purpose of holding raw data from source systems and providing a location for transient tables that are part of the transformation steps. Depending on the design methodology and ETL toolset the purpose of the staging area varies slightly but the target audience is always simply the ETL process and the Data Engineers who are responible for developing and maintaing the ETL. This doesn't negate the need the data governance that is required in a Data Lake but it does simplify it significantly when compared to the multitude of users and processes which may access a Data Lake.
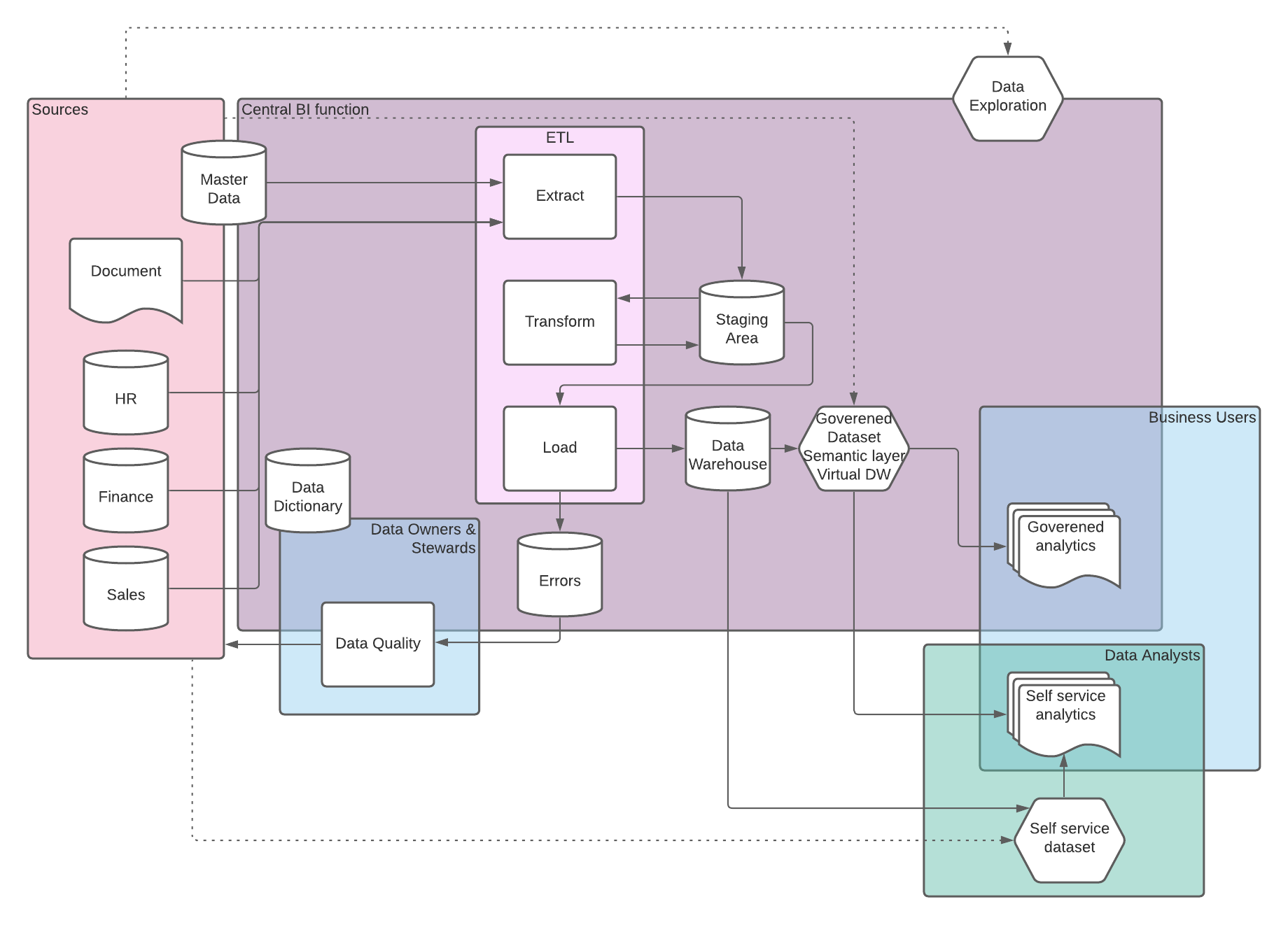 Traditional direct ETL from source system to Data Warehouse
Traditional direct ETL from source system to Data Warehouse 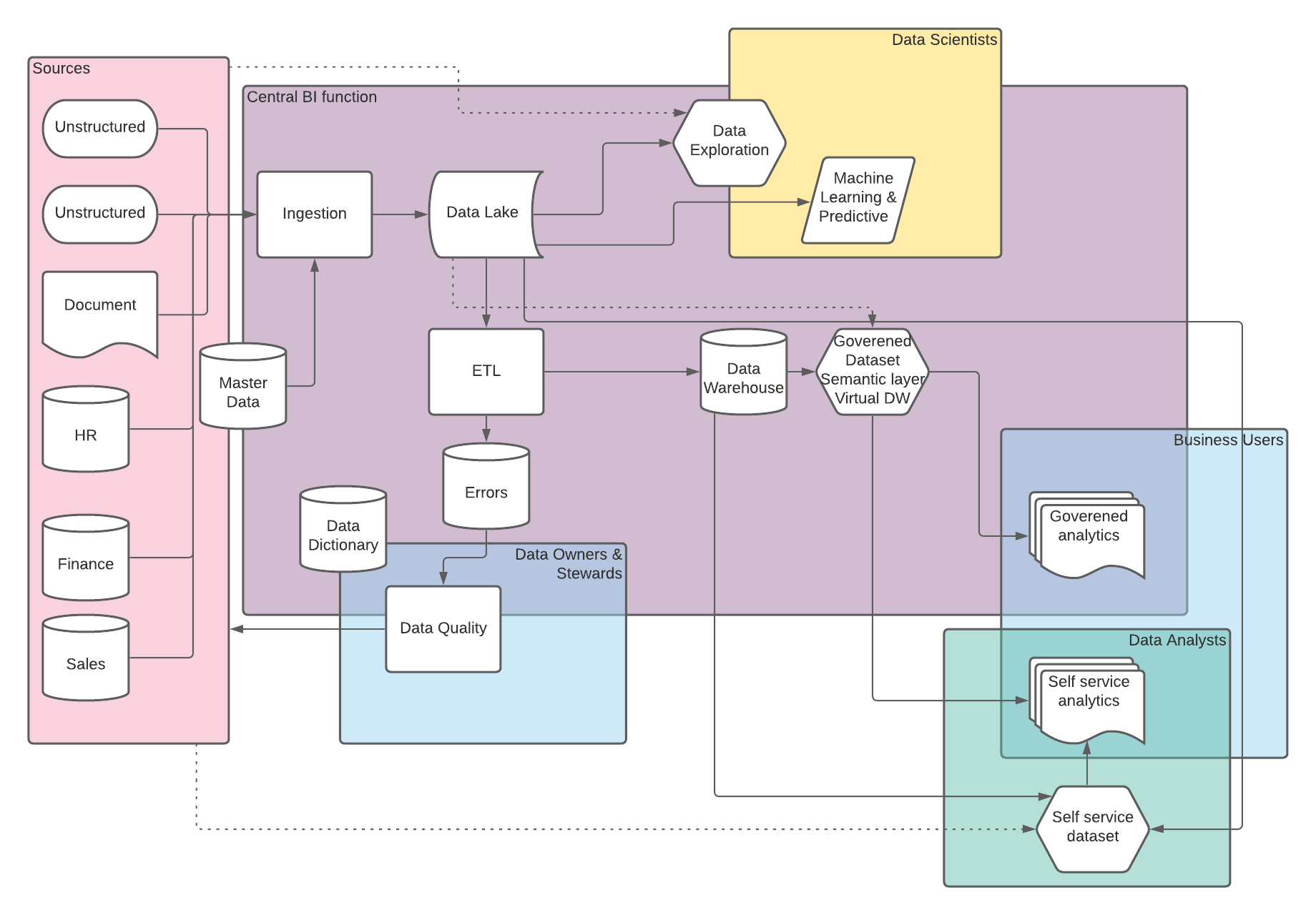 Data Warehousing with the inclusion of a Data Lake
Data Warehousing with the inclusion of a Data Lake
CONCLUSIONS
-
Depending on the toolset chosen for the Data Lake, ETL, and Data Warehouse the location and method for performing transformations and storing transient intimidate tables could be either in the Data Lake or within a sub schema of the Data Warehouse database.
-
If your ETL and Data Warehouse is the only downstream user of a Data Lake is it even a Data Lake?
-
Get your processes and policies right in terms of data governance, retention, and security.
Exploring Mapbox integration in OAC 6.2
Live location has increasingly proved important in tracking locations of objects and people in real time, especially during the pandemic when following the spread of Covid-19 became crucial in decision-making of protection protocols. Mapbox has risen in aiding numerous businesses with its high-performance platform, delivering real time mapping by collecting and processing live anonymous sensor data from users globally. OAC 6.2 was released with some Mapbox integrated features, meaning it was time to test them.
One of Mapbox’s many use cases, Vaccines.gov, devised a web application using Mapbox GL JS informing Americans of their nearest Covid-19 vaccination centres. Whilst experimenting with Mapbox in OAC, I also happened to use a Covid-19 dataset to plot some vaccinations statistics across the world. I was intrigued to see whether OAC could enable me to execute similar animations to the web application. So, I followed a video Oracle uploaded on their YouTube channel to get a gist of the features to test.
The process
This sample dataset I found on Kaggle is updated daily from the ‘Our World in Data’ GitHub repository and merged with a locations data file to distinguish the sources of these vaccinations. I imported them into DV and carried out a quick clean on a few variables I was intended to plot on a simple map visual; I replaced all null values with 0 for total_vaccinations and daily_vaccinations. I noticed the country variable was understandably being treated as an attribute, and the cleaned variables as numbers, which would help visualise the distributions easily with colour gradient scales.
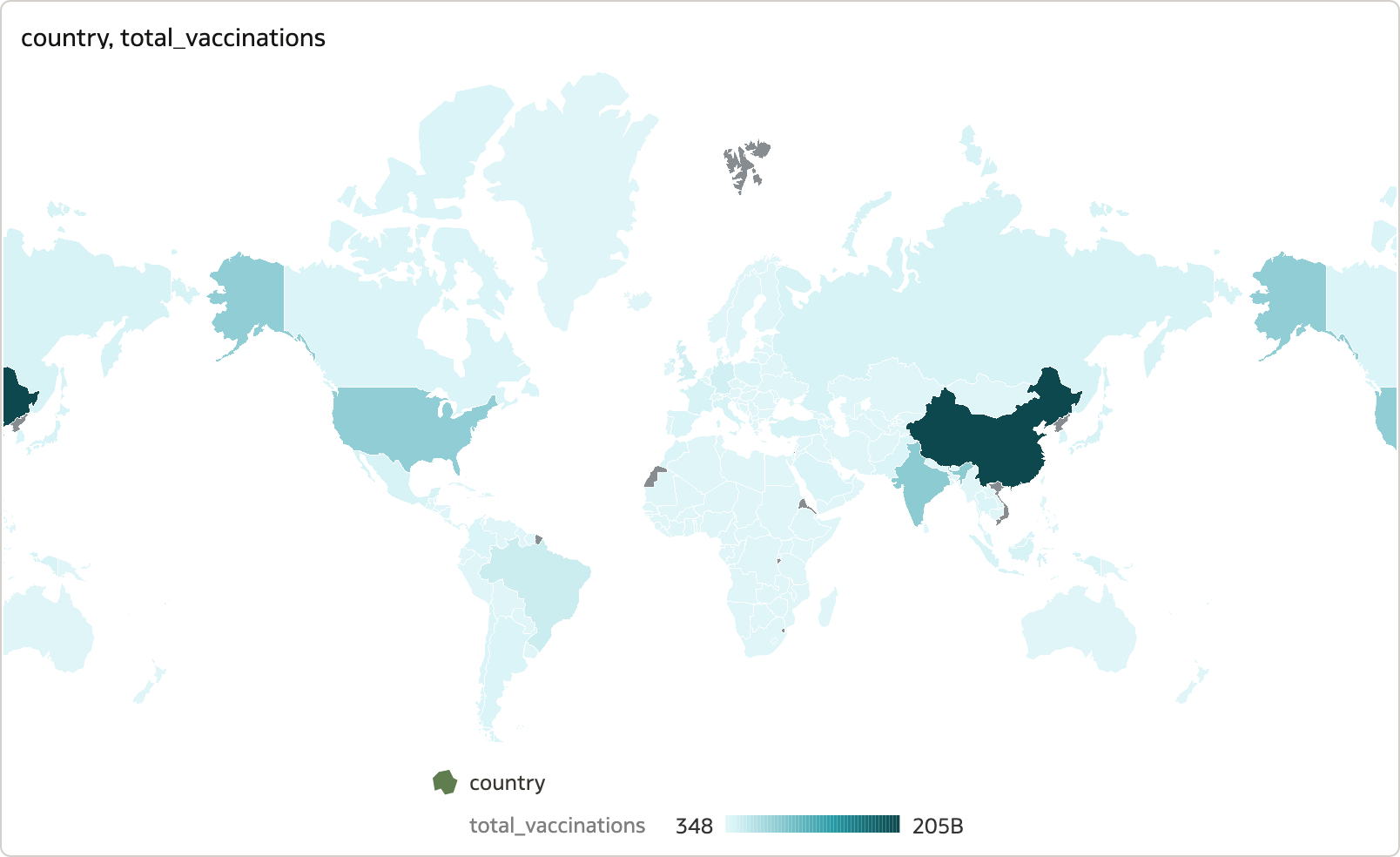
First, I plotted a map using country under the Location category, and total_vaccinations under Colour.
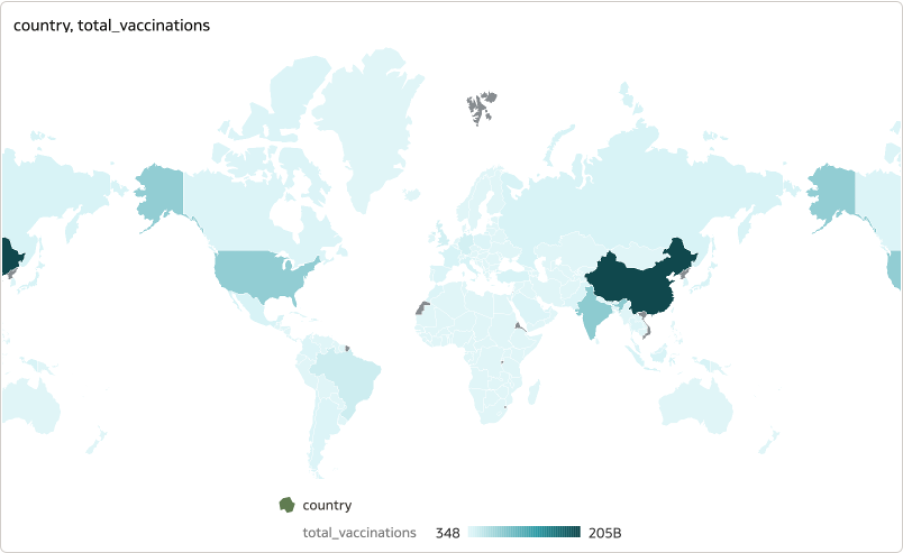 Map visualisation created using Mapbox library depicting the distribution of total vaccinations across the globe - the darker the area the higher the count.
Map visualisation created using Mapbox library depicting the distribution of total vaccinations across the globe - the darker the area the higher the count.The data is presented clearly on the map, and I could zoom in and out of specific locations seamlessly with a simple hover-and-zoom. Following the video, I added another visual depicting a table enlisting the countries and vaccines registered by each.
By selecting each field in this table, you can see the relevant country is highlighted. The first feature is the ‘Zoom to Selected’ option which directly zooms into the country of interest and can be found in the top-right menu of the map visual. Since country is only an attribute without geospatial coordinates, using the Layer Type ‘Point’ just centred the point within the country space, so leaving it as a ‘Polygon’ did not make a difference.
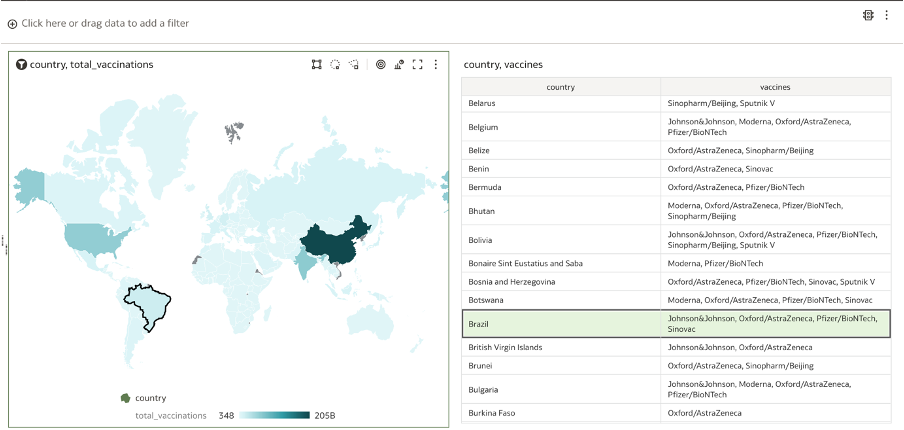 Using fields of a table as a filter to highlight regions on the map. Zoom to Selected can be used to zoom into selected regions.
Using fields of a table as a filter to highlight regions on the map. Zoom to Selected can be used to zoom into selected regions.Now for the more interesting feature, enabling the ‘Use As Filter’ on the top-left icon of the table allows for automatic zooming into the map as different fields are selected. However, you need to ensure the ‘Auto Focus on Data’ feature under ‘Map’ properties is toggled on in order to see the automatic zoom functioning well; else, the map will remain static where you left off whilst other regions will be highlighted but not shown. In addition, I experimented with some map coordinates from Kaggle that looked at statistics regarding rainfall-triggered landslides across America. I realised the latitude/longitude coordinates had to be treated as an attribute (like country above) in order to accurately plot them.
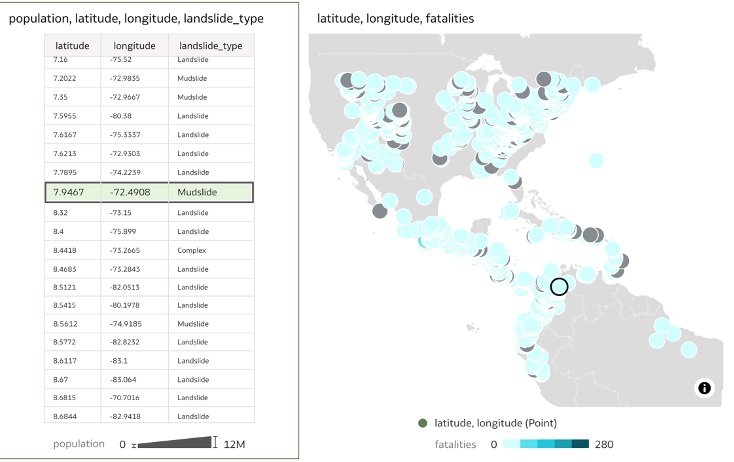 The whole table visualisation being used as a filter to highlight areas of interest on the map. With Auto-focus turned on, the map will automatically zoom into the selected area.
The whole table visualisation being used as a filter to highlight areas of interest on the map. With Auto-focus turned on, the map will automatically zoom into the selected area.Limitations
You can also add other map backgrounds to the options listed, including OracleStreetMap, Oracle BI, Oracle Maps. From Google Maps, Baidu Maps, Web Map Service, and Tiled Web Map users can only utilise the MapView library with the first two options due to legalities.
Also worth mentioning, working with Mapbox library in OAC on an older laptop and an older version of a browser may slow down loading times of visualisations in the canvas due to some fairly intensive JavaScript.
Conclusions
Overall, the Mapbox integration in OAC can execute impressive animations around accurate geospatial data, similar to many of its business use cases today. The zoom feature is seamless and helps locate areas of interest quickly to extract relevant information. There are also various map theme options to suit visualisation needs for the data you are working with.
Text mining in R
As data becomes increasingly available in the world today the need to organise and understand it also increases. Since 80% of data out there is in unstructured format, text mining becomes an extremely valuable practice for organisations to generate helpful insights and improve decision-making. So, I decided to experiment with some data in the programming language R with its text mining package “tm” – one of the most popular choices for text analysis in R, to see how helpful the insights drawn from the social media platform Twitter were in understanding people’s sentiment towards the US elections in 2020.
What is Text Mining?
Unstructured data needs to be interpreted by machines in order to understand human languages and extract meaning from this data, also known as natural language processing (NLP) – a genre of machine learning. Text mining uses NLP techniques to transform unstructured data into a structured format for identifying meaningful patterns and new insights.
A fitting example would be social media data analysis; since social media is becoming an increasingly valuable source of market and customer intelligence, it provides us raw data to analyse and predict customer needs. Text mining can also help us extract sentiment behind tweets and understand people’s emotions towards what is being sold.
Setting the scene
Which brings us to my analysis here on a dataset of tweets made regarding the US elections that took place in 2020. There were over a million tweets made about Donald Trump and Joe Biden which I put through R’s text mining tools to draw some interesting analytics and see how they measure up against the actual outcome – Joe Biden’s victory. My main aim was to perform sentiment analysis on these tweets to gain a consensus on what US citizens were feeling in the run up to the elections, and whether there was any correlation between these sentiments and the election outcome.
I found the Twitter data on Kaggle, containing two datasets: one of tweets made on Donald Trump and the other, Joe Biden. These tweets were collected using the Twitter API where the tweets were split according to the hashtags ‘#Biden’ and ‘#Trump’ and updated right until four days after the election – when the winner was announced after delays in vote counting. There was a total of 1.72 million tweets, meaning plenty of words to extract emotions from.
The process
I will outline the process of transforming the unstructured tweets into a more intelligible collection of words, from which sentiments could be extracted. But before I begin, there are some things I had to think about for processing this type of data in R:
1. Memory space – Your laptop may not provide you the memory space you need for mining a large dataset in RStudio Desktop. I used RStudio Server on my Mac to access a larger CPU for the size of data at hand.
2. Parallel processing – I first used the ‘parallel’ package as a quick fix for memory problems encountered creating the corpus. But I continued to use it for improved efficiency even after moving to RStudio Server, as it still proved to be useful.
3. Every dataset is different – I followed a clear guide on sentiment analysis posted by Sanil Mhatre. But I soon realised that although I understood the fundamentals, I would need to follow a different set of steps tailored to the dataset I was dealing with.
First, all the necessary libraries were downloaded to run the various transformation functions. tm, wordcloud, syuzhet are for text mining processes. stringr, for stripping symbols from tweets. parallel, for parallel processing of memory consuming functions. ggplot2, for plotting visualisations.
I worked on the Biden dataset first and planned to implement the same steps on the Trump dataset given everything went well the first time round. The first dataset was loaded in and stripped of all columns except that of tweets as I aim to use just tweet content for sentiment analysis.
The next steps require parallelising computations. First, clusters were set up based on (the number of processor cores – 1) available in the server; in my case, 8-1 = 7 clusters. Then, the appropriate libraries were loaded into each cluster with ‘clusterEvalQ’ before using a parallelised version of ‘lapply’ to apply the corresponding function to each tweet across the clusters. This is computationally efficient regardless of the memory space available.
So, the tweets were first cleaned by filtering out the retweet, mention, hashtag and URL symbols that cloud the underlying information. I created a larger function with all relevant subset functions, each replacing different symbols with a space character. This function was parallelised as some of the ‘gsub’ functions are inherently time-consuming.
A corpus of the tweets was then created, again with parallelisation. A corpus is a collection of text documents (in this case, tweets) that are organised in a structured format. ‘VectorSource’ interprets each element of the character vector of tweets as a document before ‘Corpus’ organises these documents, preparing them to be cleaned further using some functions provided by tm. Steps to further reduce complexity of the corpus text being analysed included: converting all text to lowercase, removing any residual punctuation, stripping the whitespace (especially that introduced in the customised cleaning step earlier), and removing English stopwords that do not add value to the text.
The corpus list had to be split into a matrix, known as Term Document Matrix, describing the frequency of terms occurring in each document. The rows represent terms, and columns documents. This matrix was yet too large to process further without removing any sparse terms, so a sparsity level of 0.99 was set and the resulting matrix only contained terms appearing in at least 1% of the tweets. It then made sense to cumulate sums of each term across the tweets and create a data frame of the terms against their calculated cumulative frequencies. I went on to only experiment with wordclouds initially to get a sense of the output words. Upon observation, I realised common election terminology and US state names were also clouding the tweets, so I filtered out a character vector of them i.e. ‘trump’, ‘biden’, ‘vote’, ‘Pennsylvania’ etc. alongside more common Spanish stopwords without adding an extra translation step. My criterion was to remove words that would not logically fit under any NRC sentiment category (see below). This removal method can be confirmed to work better than the one tm provides, which essentially rendered useless and filtered none of the specified words. It was useful to watch the wordcloud distribution change as I removed corresponding words; I started to understand whether the outputted words made sense regarding the elections and the process they were put through.
The entire process was executed several times, involving adjusting parameters (in this case: the sparsity value and the vector of forbidden words), and plotting graphical results to ensure its reliability before proceeding to do the same on the Trump dataset. The process worked smoothly and the results were ready for comparison.
The results
First on the visualisation list was wordclouds – a compact display of the 100 most common words across the tweets, as shown below.
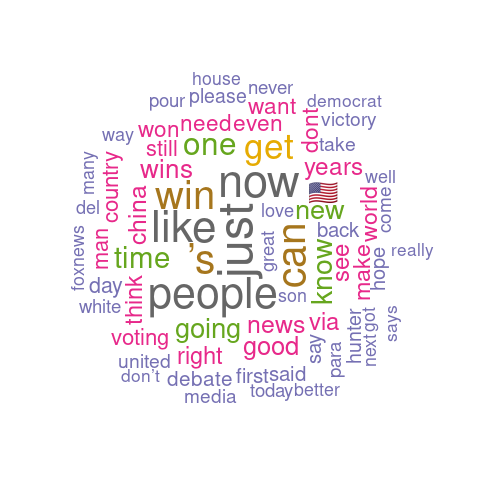 Joe Biden's analysis wordcloud
Joe Biden's analysis wordcloud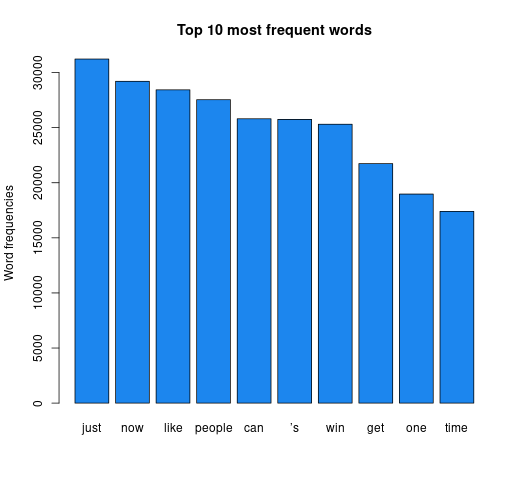 Joe Biden's analysis barplot
Joe Biden's analysis barplot Donal Trump's analysis wordcloud
Donal Trump's analysis wordcloud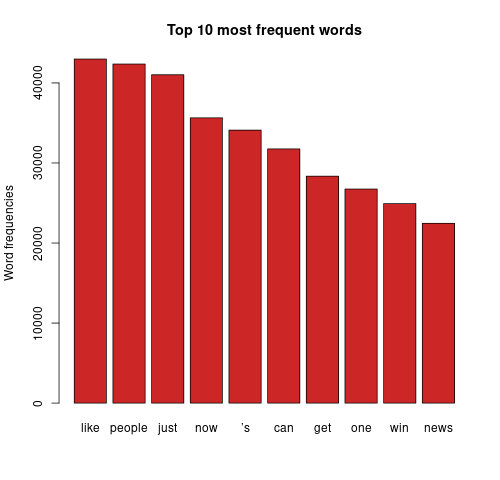 Donald Trump's analysis barplot
Donald Trump's analysis barplotThe bigger the word, the greater its frequency in tweets. Briefly, it appears the word distribution for both parties are moderately similar, with the biggest words being common across both clouds. This can be seen on the bar charts on the right, with the only differing words being ‘time’ and ‘news’. There remain a few European stopwords tm left in both corpora, the English ones being more popular. However, some of the English ones can be useful sentiment indicators e.g., ‘can’ could indicate trust. Some smaller words are less valuable as they cause ambiguity in categorisation without a clear context e.g., ‘just’, ‘now’, and ‘new’ may be coming from ‘new york’ or pointing to anticipation for the ‘new president’. Nonetheless, there are some reasonable connections between the words and each candidate; some words in Biden’s cloud do not appear in Trump’s, such as ‘victory’, ‘love’, ‘hope’. ‘Win’ is bigger in Biden’s cloud, whilst ‘white’ is bigger in Trump’s cloud as well as occurrences of ‘fraud’. Although many of the terms lack context for us to base full judgement upon, we already get a consensus of the kind of words being used in connotation to each candidate.
Analysing further, emotion classification was performed to identify the distribution of emotions present in the run up to the elections. The syuzhet library adopts the NRC Emotion Lexicon – a large, crowd-sourced dictionary of words tallied against eight basic emotions and two sentiments: anger, anticipation, disgust, fear, joy, sadness, surprise, trust, negative, positive respectively. The terms from the matrix were tallied against the lexicon and the cumulative frequency was calculated for each sentiment. Using ggplot2, a comprehensive bar chart was plotted for both datasets, as shown below.
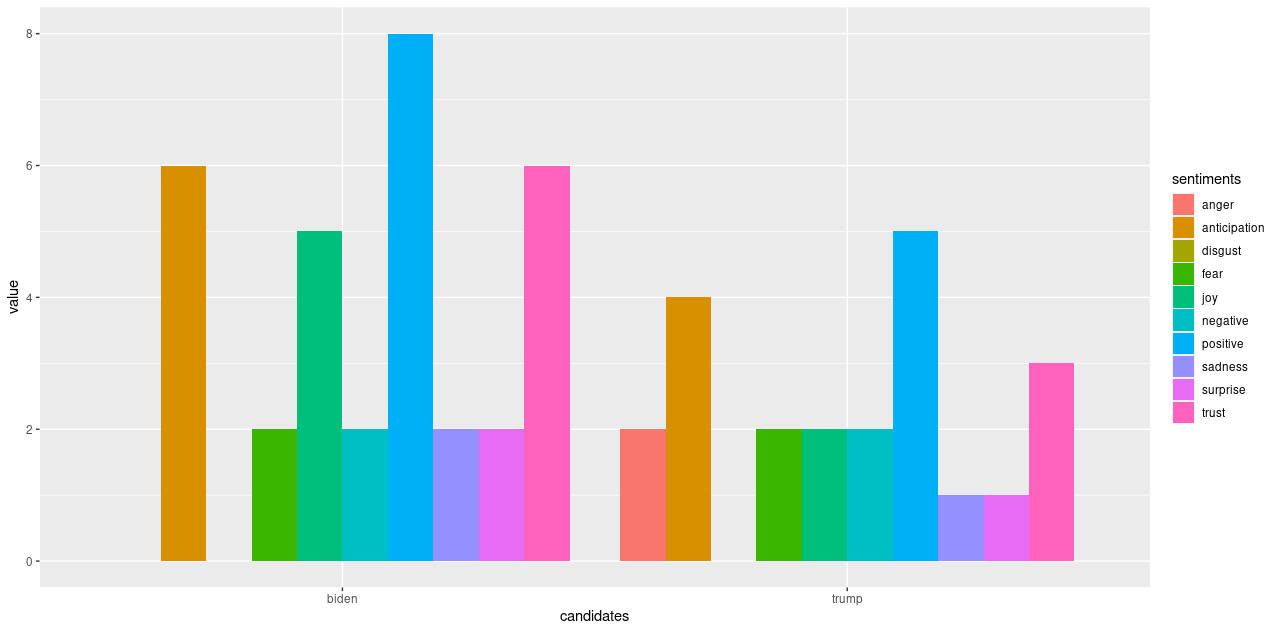 Side-by-side comparison of Biden and Trump's sentiment distribution.
Side-by-side comparison of Biden and Trump's sentiment distribution.Some revealing insights can be drawn here. Straight away, there is an absence of anger and disgust in Biden’s plot whilst anger is very much present in that of Trump’s. There is 1.6 times more positivity and 2.5 times more joy pertaining Biden, as well as twice the amount of trust and 1.5 times more anticipation about his potential. This is strong data supporting him. Feelings of fear and negativity, however, are equal in both; perhaps the audience were fearing the other party would win, or even what America’s future holds regarding either outcome. There was also twice the sadness and surprise pertaining Biden, which also makes me wonder if citizens are expressing potential emotions they would feel if Trump won (since the datasets were only split based on hashtags), alongside being genuinely sad or surprised that Biden is one of their options.
In the proportional bar charts, there is a wider gap between positivity and negativity regarding Biden than of Trump, meaning a lower proportion of people felt negatively about Biden. On the other hand, there is still around 13% trust in Trump, and a higher proportion of anticipation about him. Only around 4% of the words express sadness and surprise for him which is around 2% lower than for Biden – intriguing. We also must remember to factor in the period after the polls opened when the results were being updated and broadcasted, which may have also affected people’s feelings – surprise and sadness may have risen for both Biden and Trump supporters whenever Biden took the lead. Also, there was a higher proportion fearing Trump’s position, and the anger may have also creeped in as Trump’s support coloured the bigger states.
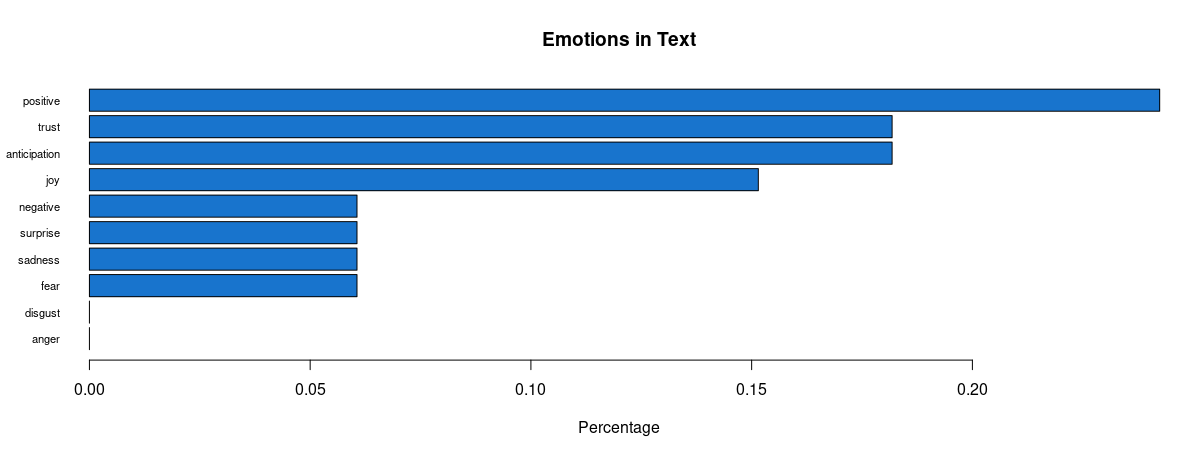 Proportional distribution of Biden-related sentiments
Proportional distribution of Biden-related sentiments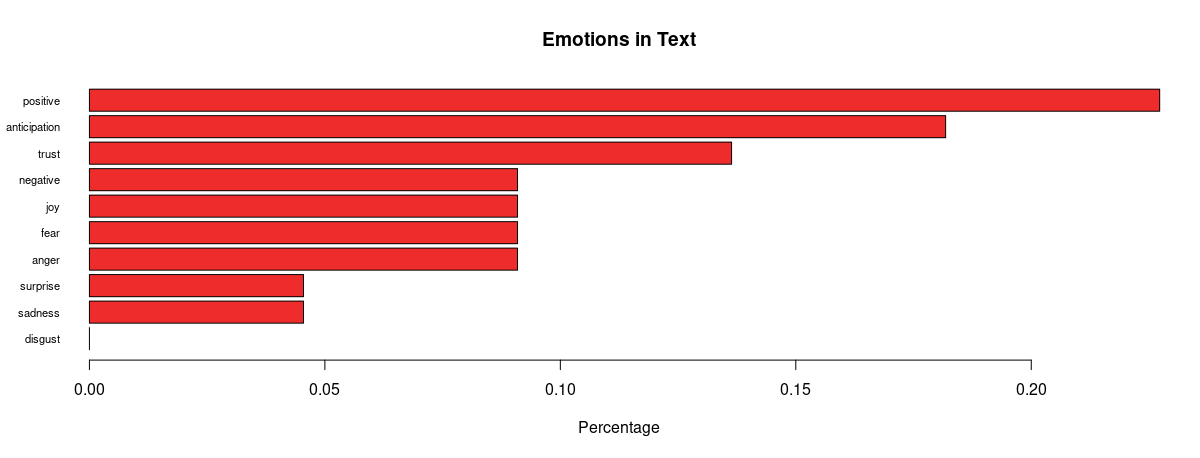 Proportional distribution of Trump-related sentiments
Proportional distribution of Trump-related sentiments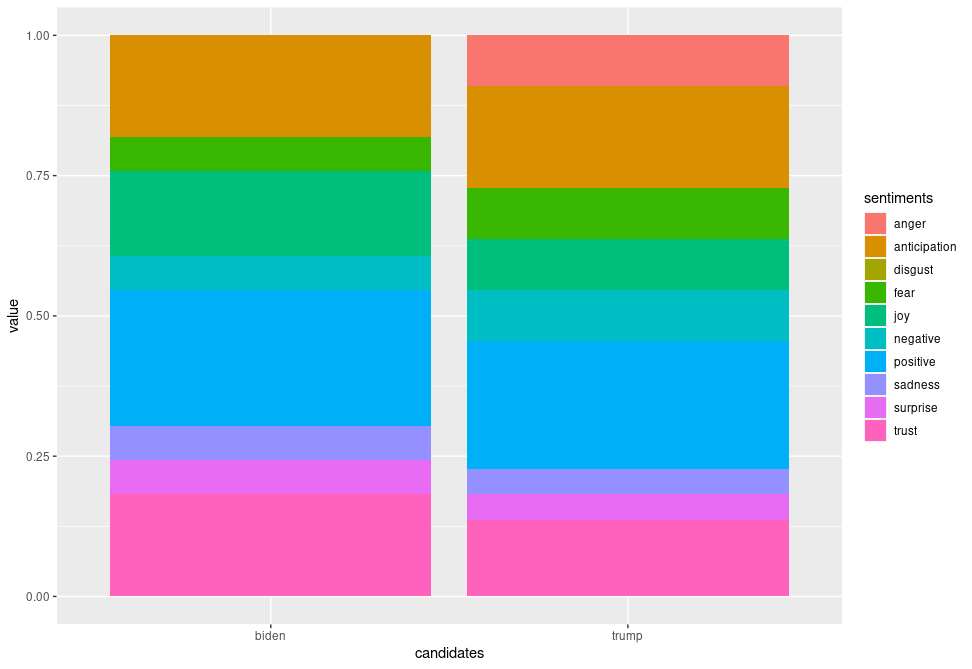 Side-by-side comparison of proportional sentiment distribution
Side-by-side comparison of proportional sentiment distributionConclusions
Being on the other side of the outcome, it is more captivating to observe the distribution of sentiments across Twitter data collected through the election period. Most patterns we observed from the data allude to predicting Joe Biden as the next POTUS, with a few exceptions when a couple of negative emotions were also felt regarding the current president; naturally, not everyone will be fully confident in every aspect of his pitch. Overall, however, we saw clear anger only towards Trump along with less joy, trust and anticipation. These visualisations, plotted using R’s tm package in a few lines of code, helped us draw compelling insights that supported the actual election outcome. It is indeed impressive how text mining can be performed at ease in R (once the you have the technical aspects figured out) to create inferential results instantly.
Nevertheless, there were some limitations. We must consider that since the tweets were split according to the hashtags ‘#Biden’ and ‘#Trump’, there is a possibility these tweets appear in both datasets. This may mean an overspill of emotions towards Trump in the Biden dataset and vice versa. Also, the analysis would’ve been clearer if we contextualised the terms’ usage; maybe considering phrases instead would build a better picture of what people were feeling. Whilst plotting the wordclouds, as I filtered out a few foreign stopwords more crept into the cloud each time, which calls for a more solid translation step before removing stopwords, meaning all terms would then be in English. I also noted that despite trying to remove the “ ’s” character, which was in the top 10, it still filtered through to the end, serving as an anomaly in this experiment as every other word in my custom vector was removed.
This experiment can be considered a success for an initial dip into the world of text mining in R, seeing that there is relatively strong correlation between the prediction and the outcome. There are several ways to improve this data analysis which can be aided with further study into various areas of text mining, and then exploring if and how R’s capabilities can expand to help us achieve more in-depth analysis.
My code for this experiment can be found here.
Rittman Mead Sponsor Fastnet Entry 2021 Part 2
It started well… we left the pontoon in strong winds and heavy rain. Before the start of Fastnet everybody has to sail past an entry gate with storm sails or equivalent flying. The winds were strong enough to sail with them and a bit of engine assist so we enjoyed a two hour wet and windy sail to Cowes.

Having passed through the entry gate we headed back down wind and put the storm sails away. We put two reefs in the main and headed back towards the start line. Unfortunately shortly after we collided with another race boat.
Nobody is hurt but the boats are damaged and we had to retire.
There is a huge amount of preparation and planning put into entering and starting these events. Training, qualifying miles meticulous boat preparation, routing, monitoring weather, victualing. To end the race is a terrible blow.
Rittman Mead Sponsor Fastnet Entry 2021
Part one.
In 2002 my wife Val and I decided to buy our first yacht. We lived in the Brighton so it seemed to make sense. In 2005 we replaced our first boat with a Sigma 400. A Sigma is a well made boat so it seemed logical she needed to be used properly; we decided to to sell everything and travel. I knew Jon Mead from a large gnarly migration project in Liverpool and he too lived in Brighton, so joined us racing for a season before we left. In 2006 Mr Mead joined us for a little sail across the atlantic (20 days). We were inexperienced as a crew and skipper but we had "fun" and survived.
Here we are again ..
In 2016 over a few glasses of wine with friends, heavily influenced by the wine we decided to enter Fastnet 2017. Fastnet is an offshore sailing race from Cowes to the Fastnet rock Southern Ireland and back to Plymouth, about 600 miles. Fastnet happens every two years and has been running since 1925. The race is organised by the Royal Ocean Racing Club (RORC).
2017 was rather successful, we had crew, a mixture of experience and completed qualifying before then going on to complete the race.
In 2019 Val and I attempted the race double handed, quite a challenge on a Sigma 400 more suited to a crew of burley men. However things did not go as planned. A number of niggles, concerns about the rudder bearings, some rigging issues, tiredness and weather finally broke us.
So back to here we are again.. 2021 we were planning to sail with two friends currently living in Denmark. Covid and travel has meant they can no longer join us so back to double handing.
Why the blog? Well Rittman Mead has kindly sponsored some of our kit for the race. Well why not after all we are an Oracle partner and Larry loves a sail. There is a lovely new Spinnaker, 96 square meters of sail branded of course with Rittman Mead and we have some HH crew hoodies to keep us warm on the trip. Thanks Mr Mead.
Fingers crossed this year is a good one. Oh another thing to mention, this year the race is controversially changing. It is now about 100 miles longer and finishes in Cherbourg. We won't be stopping as, well you know, Covid so an additional 90 miles for our return after going over the finish.
Track us on Intemperance here https://www.rolexfastnetrace.com/en/follow
Oh this doesn't look great ..
Part two of Fastnet to follow…
Sql2Odi now supports the WITH statement
The Rittman Mead's Sql2Odi tool that converts SQL SELECT statements to ODI Mappings, now supports the SQL WITH statement as well. (For an overview of our tool's capabilities, please refer to our blog posts here and here.)
The Case for WITH StatementsIf a SELECT statement is complex, in particular if it queries data from multiple source tables and relies on subqueries to do so, there is a good chance that rewriting it as a WITH statement will make it easier to read and understand. Let me show you what I mean...
SELECT
LAST_NAME,
FIRST_NAME,
LAST_NAME || ' ' || FIRST_NAME AS FULL_NAME,
AGE,
COALESCE(LARGE_CITY.CITY, ALL_CITY.CITY) CITY,
LARGE_CITY.POPULATION
FROM
ODI_DEMO.SRC_CUSTOMER CST
INNER JOIN ODI_DEMO.SRC_CITY ALL_CITY ON ALL_CITY.CITY_ID = CST.CITY_ID
LEFT JOIN (
SELECT
CITY_ID,
UPPER(CITY) CITY,
POPULATION
FROM ODI_DEMO.SRC_CITY
WHERE POPULATION > 750000
) LARGE_CITY ON LARGE_CITY.CITY_ID = CST.CITY_ID
WHERE AGE BETWEEN 25 AND 45This is an example from my original blog posts. Whilst one could argue that the query is not that complex, it does contain a subquery, which means that the query does not read nicely from top to bottom - you will likely need to look at the subquery first for the master query to make sense to you.
Same query, rewritten as a WITH statement, looks like this:
WITH
BASE AS (
SELECT
LAST_NAME,
FIRST_NAME,
LAST_NAME || ' ' || FIRST_NAME AS FULL_NAME,
AGE,
CITY_ID
FROM
ODI_DEMO.SRC_CUSTOMER CST
),
LARGE_CITY AS (
SELECT
CITY_ID,
UPPER(CITY) CITY,
POPULATION
FROM ODI_DEMO.SRC_CITY
WHERE POPULATION > 750000
),
ALL_DATA AS (
SELECT
LAST_NAME,
FIRST_NAME,
FULL_NAME,
AGE,
COALESCE(LARGE_CITY.CITY, ALL_CITY.CITY) CITY,
LARGE_CITY.POPULATION
FROM
BASE CST
INNER JOIN ODI_DEMO.SRC_CITY ALL_CITY ON ALL_CITY.CITY_ID = CST.CITY_ID
LEFT JOIN LARGE_CITY ON LARGE_CITY.CITY_ID = CST.CITY_ID
WHERE AGE BETWEEN 25 AND 45
)
SELECT * FROM ALL_DATAWhilst it is longer, it reads nicely from top to bottom. And the more complex the query, the more the comprehensibility will matter.
The first version of our Sql2Odi tool did not support WITH statements. But it does now.
The process is same old - first we add the two statements to our metadata table, add some additional data to it, like the ODI Project and Folder names, the name of the Mapping, the Target table that we want to populate and how to map the query result to the Target table, names of Knowledge Modules and their config, etc.
After running the Sql2Odi Parser, which now happily accepts WITH statements, and the Sql2Odi ODI Content Generator, we end up with two mappings:
What do we see when we open the mappings?
The original SELECT statement based mappings is generated like this:
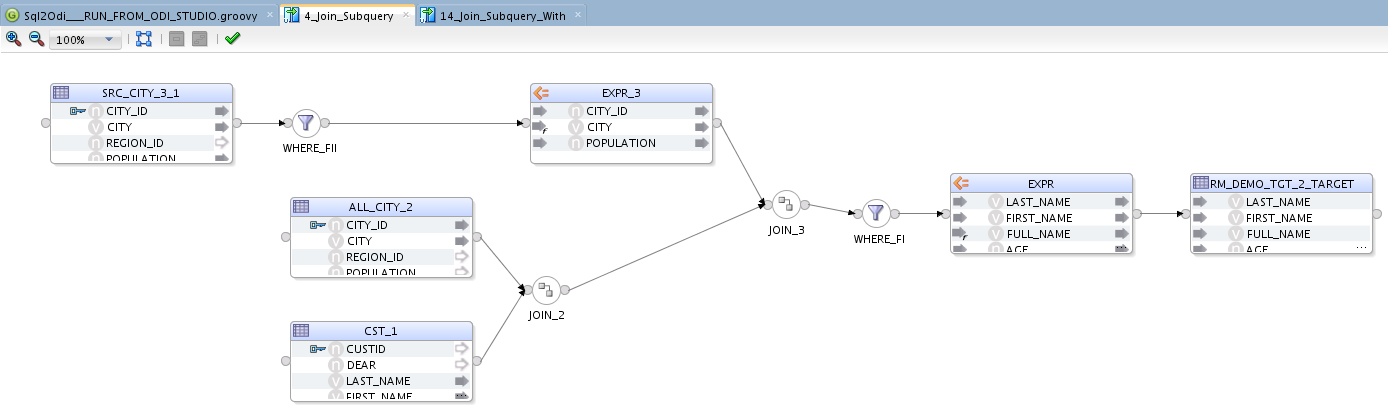
The new WITH statement mapping, though it queries the same data in pretty much the same way, is more verbose:

The additional EXPRESSION components are added to represent references to the WITH subqueries. While the mapping is now busier than the original SELECT, there should be no noticeable performance penalty. Both mappings generate the exact same output.
Joining Data in OAC
One of the new features in OAC 6.0 was Multi Table Datasets, which provides another way to join tables to create a Data Set.
We can already define joins in the RPD, use joins in OAC’s Data Flows and join Data Sets using blending in DV Projects, so I went on a little quest to compare the pros and cons of each of the methods to see if I can conclude which one works best.
What is a data join?Data in databases is generally spread across multiple tables and it is difficult to understand what the data means without putting it together. Using data joins we can stitch the data together, making it easier to find relationships and extract the information we need. To join two tables, at least one column in each table must be the same. There are four available types of joins I’ll evaluate:
1. Inner join - returns records that have matching values in both tables. All the other records are excluded.
2. Left (outer) join - returns all records from the left table with the matched records from the right table.
3. Right (outer) join - returns all records from the right table with the matched records from the left table.
4. Full (outer) join - returns all records when there is a match in either left or right tables.
Each of the three approaches give the developer different ways and places to define the relationship (join) between the tables. Underpinning all of the approaches is SQL. Ultimately, OAC will generate a SQL query that will retrieve data from the database, so to understand joins, let’s start by looking at SQL Joins
SQL JoinsIn an SQL query, a JOIN clause is used to execute this function. Here is an example:
SELECT EMP.id, EMP.name, DEPT.stream
FROM EMP
INNER JOIN DEPT ON DEPT.id = EMP.id; 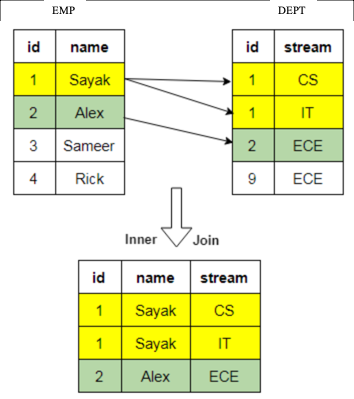 Figure 1 - Example of an inner join on a sample dataset.
Figure 1 - Example of an inner join on a sample dataset.Now that we understand the basic concepts, let’s look at the options available in OAC.
Option 1: RPD JoinsThe RPD is where the BI Server stores its metadata. Defining joins in the RPD is done in the Admin Client Tool and is the most rigorous of the join options. Joins are defined during the development of the RPD and, as such, are subject to the software development lifecycle and are typically thoroughly tested.
End users access the data through Subject Areas, either using classic Answers and Dashboards, or DV. This means the join is automatically applied as fields are selected, giving you more control over your data and, since the RPD is not visible to end-users, avoiding them making any incorrect joins.
The main downside of defining joins in the RPD is that it’s a slower process - if your boss expects you to draw up some analyses by the end of the day, you may not make the deadline using the RPD. It takes time to organise data, make changes, then test and release the RPD.
Join DetailsThe Admin Client Tool allows you to define logical and physical tables, aggregate table navigation, and physical-to-logical mappings. In the physical layer you define primary and foreign keys using either the properties editor or the Physical Diagram window. Once the columns have been mapped to the logical tables, logical keys and joins need to be defined. Logical keys are generally automatically created when mapping physical key columns. Logical joins do not specify join columns, these are derived from the physical mappings.
You can change the properties of the logical join; in the Business Model Diagram you can set a driving table (which optimises how the BI Server process joins when one table is smaller than the other), the cardinality (which expresses how rows in one table are related to rows in the table to which it is joined), and the type of join.
Driving tables only activate query optimisation within the BI Server when one of the tables is much smaller than the other. When you specify a driving table, the BI Server only uses it if the query plan determines that its use will optimise query processing. In general, driving tables can be used with inner joins, and for outer joins when the driving table is the left table for a left outer join, or the right table for a right outer join. Driving tables are not used for full outer joins.
The Physical Diagram join also gives you an expression editor to manually write SQL for the join you want to perform on desired columns, introducing complexity and flexibility to customise the nature of the join. You can define complex joins, i.e. those over non-foreign key and primary key columns, using the expression editor rather than key column relationships. Complex joins are not as efficient, however, because they don’t use key column relationships.
 Figure 3 - Business Model Diagram depicting joins made between three tables in the RPD.
Figure 3 - Business Model Diagram depicting joins made between three tables in the RPD.It’s worth addressing a separate type of table available for creation in the RPD – lookup tables. Lookup tables can be added to reference both physical and logical tables, and there are several use cases for them e.g., pushing currency conversions to separate calculations. The RPD also allows you to define a logical table as being a lookup table in the common use case of making ID to description mappings.
Lookup tables can be sparse and/or dense in nature. A dense lookup tables contains translations in all languages for every record in the base table. A sparse lookup table contains translations for only some records in the base tables. They can be accessed via a logical calculation using DENSE or SPARSE lookup function calls. Lookup tables are handy as they allow you to model the lookup data within the business model; they’re typically used for lookups held in different databases to the main data set.
Multi-database joins allow you to join tables from across different databases. Even though the BI Server can optimise the performance of multi-database joins, these joins are significantly slower than those within a single database.
Option 2: Data Flow JoinsData Flows provide a way to transform data in DV. The data flow editor gives us a canvas where we can add steps to transform columns, merge, join or filter data, plot forecasts or apply various models on our datasets.
When it comes to joining datasets, you start by adding two or more datasets. If they have one or more matching columns DV automatically detects this and joins them; otherwise, you have to manually add a ‘Join’ step and provided the columns’ data types match, a join is created.
A join in a data flow is only possible between two datasets, so if you wanted to join a third dataset you have to create a join between the output of the first and second tables and the third, and so on. You can give your join a name and description which would help keep track if there are more than two datasets involved. You can then view and edit the join properties via these nodes created against each dataset. DV gives you the standard four types of joins (Fig. 1), but they are worded differently; you can set four possible combinations for each input node by toggling between ‘All rows’ and ‘Matching rows’. That means:
Join type
Node 1
Node 2
Inner join
Matching rows
Matching rows
Left join
All rows
Matching rows
Right join
Matching rows
All rows
Full join
All rows
All rows
The table above explains which type of join can be achieved by toggling between the two drop-down options for each dataset in a data flow join.
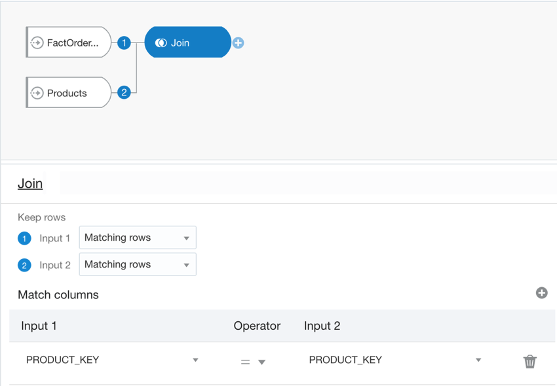 Figure 4 - Data flow editor where joins can be made and edited between two datasets.
Figure 4 - Data flow editor where joins can be made and edited between two datasets.It’s worth mentioning there is also an operator called ‘Union Rows’. You can concatenate two datasets, provided they have the same number of columns with compatible datatypes. There are a number of options to decide how you want to combine the rows of the datasets.
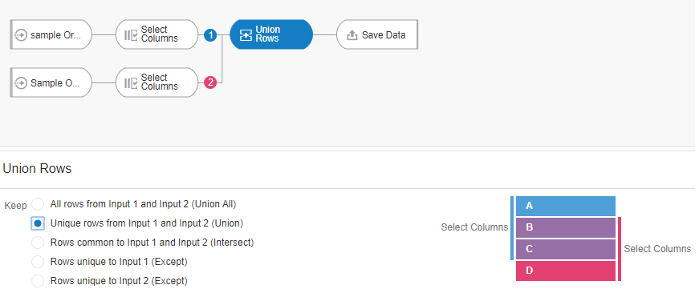 Figure 5 - Union Rows operator displaying how the choices made impact columns in the data.
Figure 5 - Union Rows operator displaying how the choices made impact columns in the data.One advantage of data flows is they allow you to materialise the data i.e. save it to disk or a database table. If your join query takes 30 minutes to run, you can schedule it to run overnight and then reports can query the resultant dataset.
However, there are limited options as to the complexity of joins you can create:
- the absence of an expression editor to define complex joins
- you cannot join more than two datasets at a time.
You can schedule data flows which would allow you to materialise the data overnight ready for when users want to query the data at the start of the day.
Data Flows can be developed and executed on the fly, unlike the longer development lifecycle of the RPD.
It should be noted that Data Flows cannot be shared. The only way around this is to export the Data Flow and have the other user import and execute it. The other user will need to be able to access the underlying Data Sets.
Option 3: Data BlendingBefore looking at the new OAC feature, there is a method already present for cross-database joins which is blending data.
Given at least two data sources, for example, a database connection and an excel spreadsheet from your computer, you can create a Project with one dataset and add the other Data Set under the Visualise tab. The system tries to find matches for the data that’s added based on common column names and compatible data types. Upon navigating back to the Data tab, you can also manually blend the datasets by selecting matching columns from each dataset. However, there is no ability to edit any other join properties.
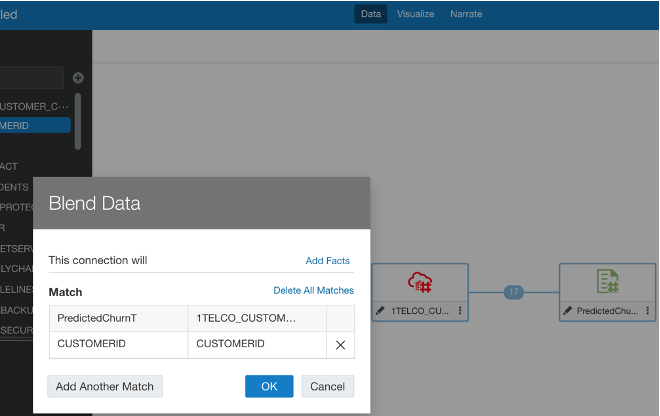 Figure 6 - Existing method of blending data by matching columns from each dataset.Option 4: Multi Table Datasets
Figure 6 - Existing method of blending data by matching columns from each dataset.Option 4: Multi Table DatasetsLastly, let’s look at the newly added feature of OAC 6.0: Multi Table Datasets. Oracle have now made it possible to join several tables to create a new Data Set in DV.
Historically you could create Data Sets from a database connection or upload files from your computer. You can now create a new Data Set and add multiple tables from the same database connection. Oracle has published a list of compatible data sources.
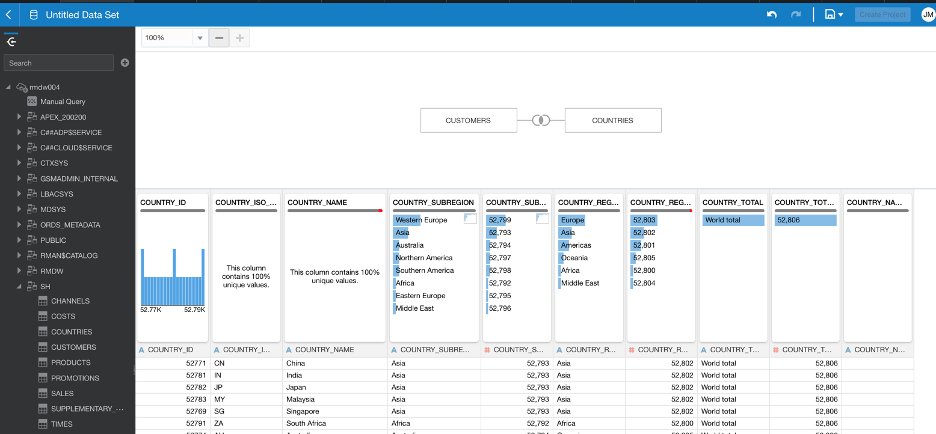 Figure 7 - Data Set editor where joins can be made between numerous datasets and their properties edited.
Figure 7 - Data Set editor where joins can be made between numerous datasets and their properties edited.Once you add your tables DV will automatically populate joins, if possible, on common column names and compatible data types.
The process works similarly to how joins are defined in Data Flows; a pop-up window displays editable properties of the join with the same complexity - the options to change type, columns to match, the operator type relating them, and add join conditions.
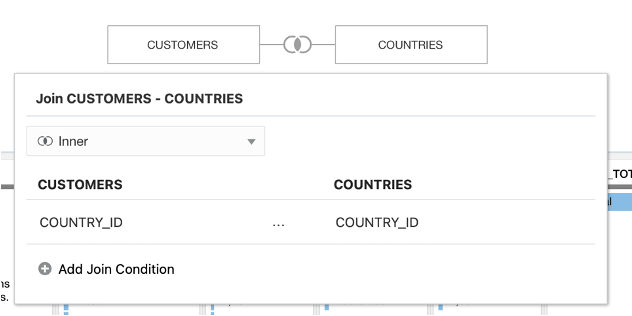 Figure 8 - Edit window for editing join properties.
Figure 8 - Edit window for editing join properties.The data preview refreshes upon changes made in the joins, making it easy to see the impact of joins as they are made.
Unlike in the RPD, you do not have to create aliases of tables in order to use them for multiple purposes; you can directly import tables from a database connection, create joins and save this Multi Table Dataset separately to then use it further in a project, for example. So, the original tables you imported will retain their original properties.
If you need to write complex queries you can use the Manual SQL Query editor to create a Data Set, but you can only use the ‘JOIN’ clause.
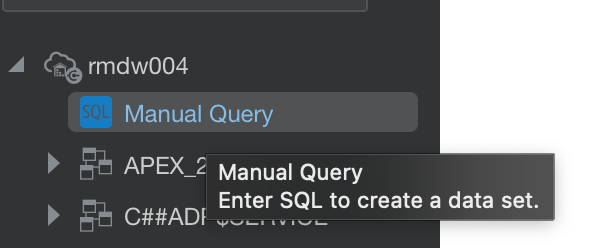 Figure 9 - Manual Query editor option under a set up database connection.So, what’s the verdict?
Figure 9 - Manual Query editor option under a set up database connection.So, what’s the verdict?Well, after experimenting with each type of joining method and talking to colleagues with experience, the verdict is: it depends on the use case.
There really is no right or wrong method of joining datasets and each approach has its pros and cons, but I think what matters is evaluating which one would be more advantageous for the particular use case at hand.
Using the RPD is a safer and more robust option, you have control over the data from start to end, so you can reduce the chance of incorrect joins. However, it is considerably slower and make not be feasible if users demand quick results. In this case, using one of the options in DV may seem more beneficial.
You could either use Data Flows, either scheduled or run manually, or Multi Table Datasets. Both approaches have less scope for making complex joins than the RPD. You can only join two Data Sets at a time in the traditional data flow, and you need a workaround in DV to join data across database connections and computer-uploaded files; so if time and efficiency is of essence, these can be a disadvantage.
l would say it’s about striking a balance between turnaround time and quality - of course both good data analysis in good time is desirable, but when it comes to joining datasets in these platforms it will be worth evaluating how the use case will benefit from either end of the spectrum.
Oracle Support Rewards
First of all, what is it?
Essentially, it’s a cashback scheme. For every Dollar, Pound, Yen, Euro you spend moving to OCI (Oracle Cloud Infrastructure), Oracle will give you 25% off your annual support bill.
It’s a great incentive for cloud adoption and has the potential to wipe out your support bill completely.
How does it work?
Here’s an example: you decide to move your on-premise data warehouse, ETL, and OBIEE systems to Oracle Cloud.
Your total annual support for all your remaining Oracle on-premise software is £100,000. Your annual OCI Universal Credits spend is £100,000. Oracle will give you 25% of as Support Rewards, equating to £25,000.
You’ve just taken a quarter off your annual support bill. You’re a hero.
But wait!
You’re not finished yet, your E-Business Suite system is looking a bit dusty, ERP Cloud is the way forward, but getting the budget has been harder than expected.
Why not try again? The more you move the higher the reward, right…
You could offset the some of the cost of the move to ERP Cloud with the savings on your on-premise support costs.
Now you’ve wiped out the annual support bill completely. Legend territory!
Total Savings
Having the possibility to reduce your annual support spend by 100% is stunning, but in the drive for cloud adoption Oracle have gone further. The Support Rewards run alongside the current Volume Discount offer. This gives the potential of having a 50% total saving.
 Support Rewards with OCI Volume Discounts
Support Rewards with OCI Volume DiscountsNow, if like me this is causing you to get rather excited feel free to get in contact. We can share our excitement and if applicable discuss some of the ways Rittman Mead can help you build your business case to modernise your product stack.
Sql2Odi, Part Two: Translate a complex SELECT statement into an ODI Mapping
What we call a complex SQL SELECT statement really depends on the context. When talking about translating SQL queries into ODI Mappings, pretty much anything that goes beyond a trivial SELECT * FROM <a_single_source_table> can be called complex.
SQL statements are meant for humans to be written and for RDBMS servers like Oracle Database to be understood and executed. RDBMS servers benefit from a wealth of knowledge about the database we are querying and are willing to give us a lot of leeway about how we write those queries, to make it as easy as possible for us. Let me show you what I mean:
SELECT
FIRST_NAME,
AGE - '5' LIE_ABOUT_YOUR_AGE,
REGION.*
FROM
CUSTOMER
INNER JOIN REGION ON "CUSTOMER_REGION_ID" = REGION.REGION_ID
We are selecting from two source tables, yet we have not bothered about specifying source tables for columns (apart from one instance in the filter). That is fine - the RDBMS server can fill that detail in for us by looking through all source tables, whilst also checking for column name duplicates. We can use numeric strings like '567' instead of proper numbers in our expressions, relying on the server to perform implicit conversion. And the * will always be substituted with a full list of columns from the source table(s).
All that makes it really convenient for us to write queries. But when it comes to parsing them, the convenience becomes a burden. However, despite lacking the knowledge the the RDBMS server possesses, we can still successfully parse and then generate an ODI Mapping for quite complex SELECT statements. Let us have a look at our Sql2Odi translator handling various challenges.
Rittman Mead's Sql2Odi Translator in Action
Let us start with the simplest of queries:
SELECT
ORDER_ID,
STATUS,
ORDER_DATE
FROM
ODI_DEMO.SRC_ORDERS
The result in ODI looks like this:
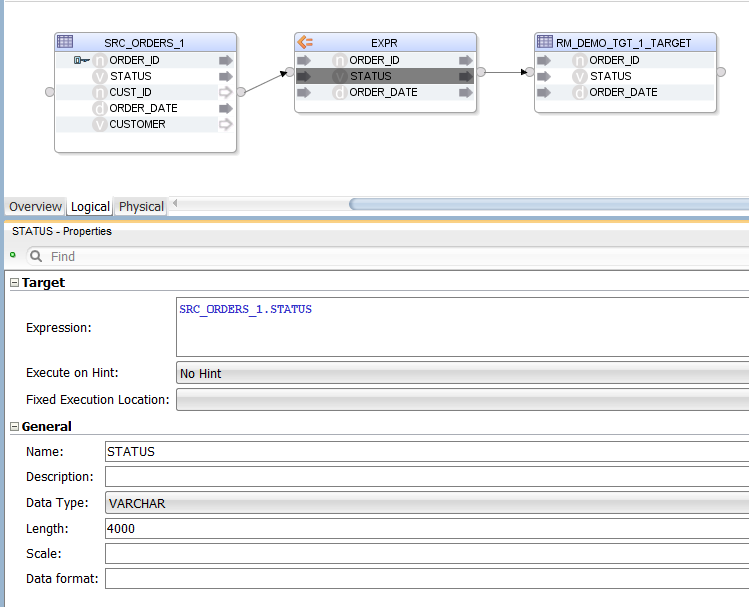
Sql2Odi has created an Expression, in which we have the list of selected columns. The columns are mapped to the target table by name (alternatively, they could be mapped by position). The target table is provided in the Sql2Odi metadata table along with the SELECT statement and other Mapping generation related configuration.
Can we replace the list of columns in the SELECT list with a *?
SELECT * FROM ODI_DEMO.SRC_ORDERS
The only difference from the previously generated Mapping is that the Expression now has a full list of source table columns. We could not get the list of those columns while parsing the statement but we can look them up from the source ODI Datastore when generating the mapping. Groovy!
Let us increase the complexity by adding a JOIN, a WHERE filter and an ORDER BY clause to the mix:
SELECT
SRC_ORDERS.*
FROM
ODI_DEMO.SRC_ORDERS
LEFT JOIN ODI_DEMO.SRC_CUSTOMER CUST ON
SRC_ORDERS.CUST_ID = CUST.CUSTID
WHERE
CUST.AGE BETWEEN 20 AND 50
ORDER BY CUST.AGE
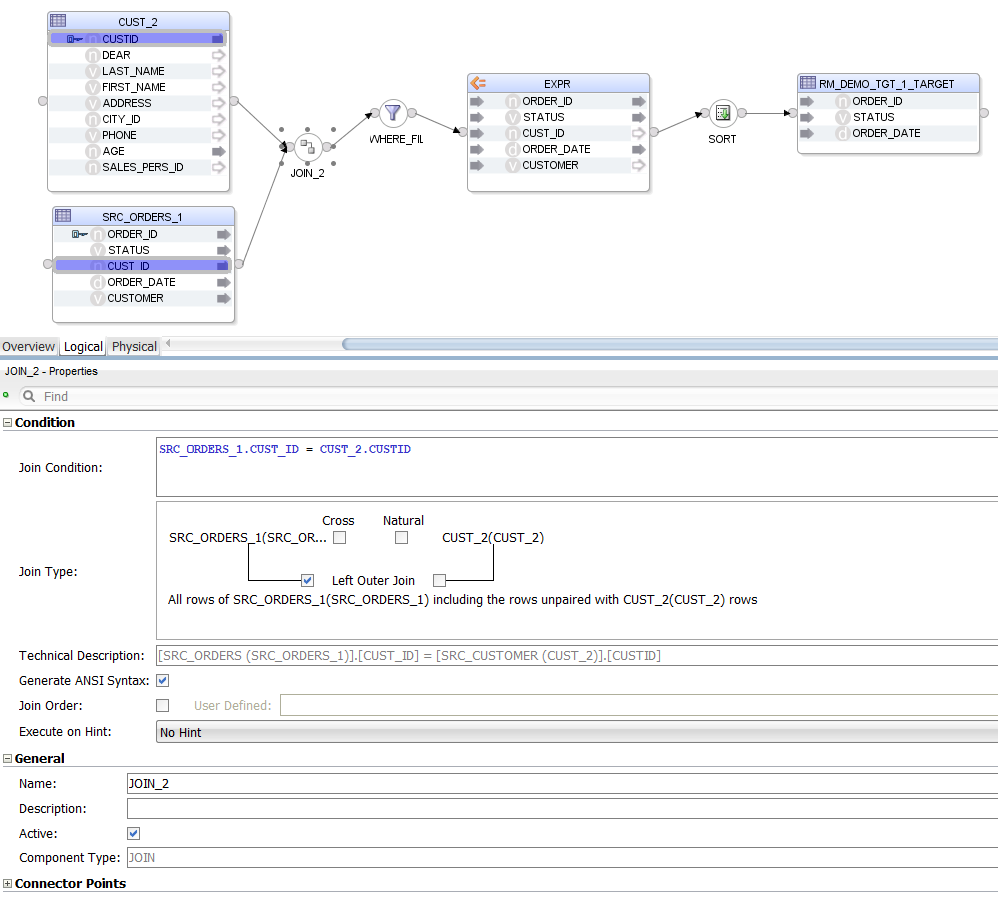
The Mapping looks more crowded now. Notice that we are selecting * from one source table only - again, that is not something that the parser alone can handle.
We are not using ODI Mapping Datasets - a design decision was made not to use them because of the way Sql2Odi handles subqueries.
Speaking of subqueries, let us give them a try - in the FROM clause you can source your data not only from tables but also from sub-SELECT statements or subqueries.
SELECT
LAST_NAME,
FIRST_NAME,
LAST_NAME || ' ' || FIRST_NAME AS FULL_NAME,
AGE,
COALESCE(LARGE_CITY.CITY, ALL_CITY.CITY) CITY,
LARGE_CITY.POPULATION
FROM
ODI_DEMO.SRC_CUSTOMER CST
INNER JOIN ODI_DEMO.SRC_CITY ALL_CITY ON ALL_CITY.CITY_ID = CST.CITY_ID
LEFT JOIN (
SELECT
CITY_ID,
UPPER(CITY) CITY,
POPULATION
FROM ODI_DEMO.SRC_CITY
WHERE POPULATION > 750000
) LARGE_CITY ON LARGE_CITY.CITY_ID = CST.CITY_ID
WHERE AGE BETWEEN 25 AND 45
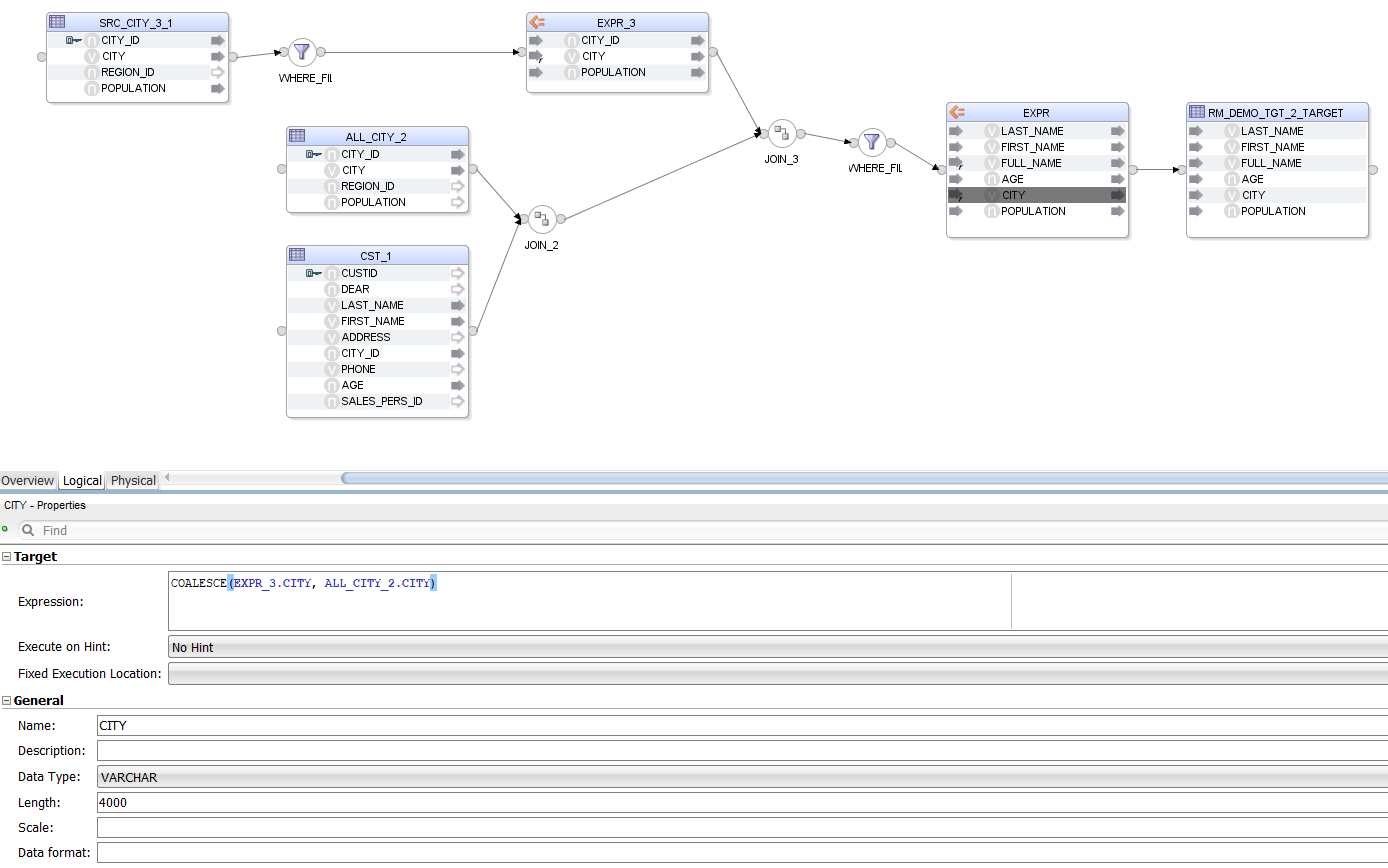
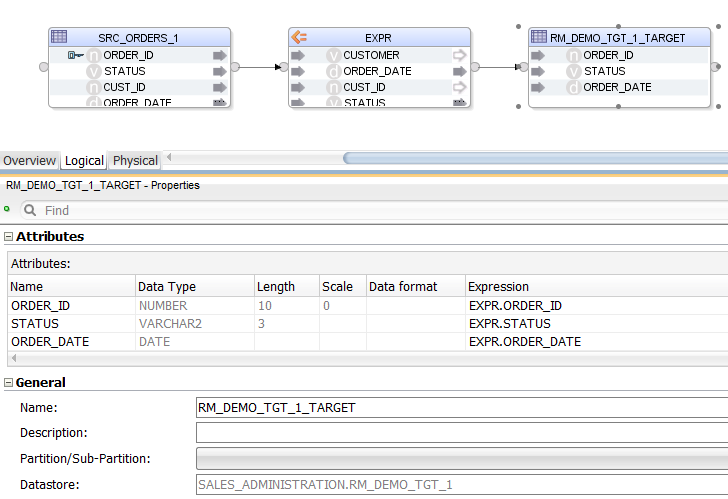
As we can see, a sub-SELECT statement is handled the same way as a source table, the only difference being that we also get a WHERE Filter and an Expression that together give us the data set of the subquery. All Components representing the subquery are suffixed with a 3 or _3_1 in the Mapping.
Now let us try Aggregates.
SELECT
REGION,
SUM(POPULATION) TOTAL_POPULATION,
ROUND(MAX(SRC_CITY.POPULATION) / 1000000) BIGGEST_CITY_POPULATION_K,
ROUND(MIN(SRC_CITY.POPULATION) / 1000000) SMALLEST_CITY_POPULATION_K
FROM
ODI_DEMO.SRC_CITY
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
WHERE
CITY_ID > 20 AND
"SRC_CITY"."CITY_ID" < 1000 AND
ODI_DEMO.SRC_CITY.CITY_ID != 999 AND
COUNTRY IN ('USA', 'France', 'Germany', 'Great Britain', 'Japan')
GROUP BY
REGION
HAVING
SUM(POPULATION) > 10000 AND
MIN(SRC_CITY.POPULATION) > 100 AND
MAX("POPULATION") > 1000 AND
AVG(ODI_DEMO.SRC_CITY.POPULATION) >= 5
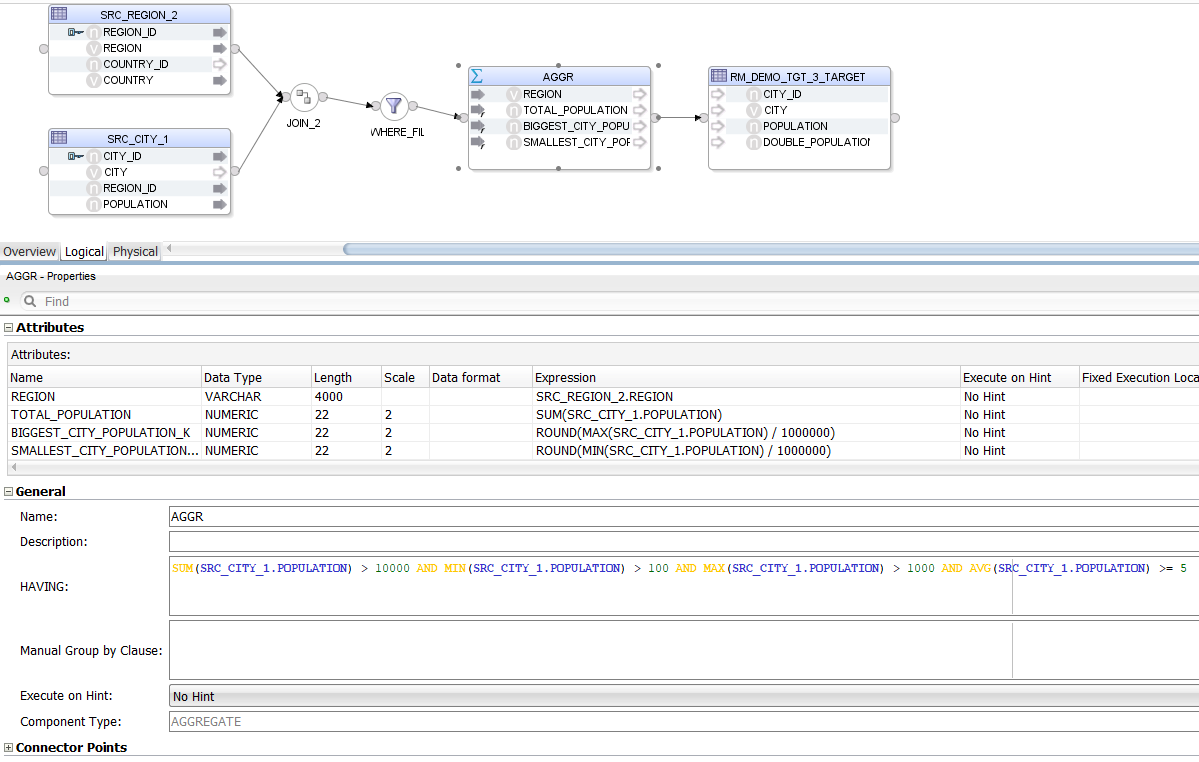
This time, instead of an Expression we have an Aggregate. The parser has no problem handling the many different "styles" of column references provided in the HAVING clause - all of them are rewritten to be understood by ODI.
Now let us throw different Expressions at it, to see how well they are handled.
SELECT
REG_COUNTRY.COUNTRY,
REG_COUNTRY.LOC,
REG_COUNTRY.NR_OF_EURO_REG,
LAST_NAME,
LAST_NAME AS SURNAME,
FIRST_NAME,
FIRST_NAME || ' ' || LAST_NAME FULL_NAME,
'String concatenation' || ' ' || FIRST_NAME || ' demo.' CONCAT_STRING,
UPPER(LAST_NAME) || ' in UpperCase' AS LAST_NAME_UPPER,
SUBSTR(TRIM(UPPER(' Name: ' || LAST_NAME || ' ' || FIRST_NAME || ' ')), 2, 10) TEXT_FUNC,
TRANSLATE(UPPER(LAST_NAME), 'AEIOU', 'XXXXX') X_LAST_NAME,
LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN,
10 + LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10P,
10 * LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10T,
INSTR(UPPER(LAST_NAME), 'MC') MC_IN_LAST,
1 + 2 + 3 + 4 +5+6+7 SIMP_SUM,
1+2-3*4/5+(6*7+8-9)/(1+2+3) SUM2,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3)) SUM2_ROUND1,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2) SUM2_ROUND2,
FLOOR(ROUND(1+2-3*4/5+(6*7+8-9), 2) / ROUND((1+2+3), 2)) SUM2_ROUND3,
SYSDATE DATE_NOW,
SYSDATE AS CUR_DAT,
1 + SYSDATE AS CURD_1,
SYSDATE + 4 AS CURD_4,
CURRENT_DATE AS CUR_ALT,
ADD_MONTHS(SYSDATE, 1) CURD_1M,
CURRENT_TIMESTAMP STAMP_NOW,
LAST_DAY(SYSDATE) LAST_CURD,
NEXT_DAY(LAST_DAY(SYSDATE), 2) LAST_NEXT_CURD,
TO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURT,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN FLOOR(345.56)
WHEN REG_COUNTRY.COUNTRY = 'Germany' THEN MONTHS_BETWEEN(SYSDATE, SYSDATE+1000)
ELSE NULL
END SIM_CASE_NUM,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN NEXT_DAY(LAST_DAY(SYSDATE+5), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN NEXT_DAY(LAST_DAY(SYSDATE+40), 2)
ELSE NULL
END SIM_CASE_DATE,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN UPPER(FIRST_NAME || ' ' || LAST_NAME)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE || ' years of pain'
ELSE NULL
END SIM_CASE_CHAR,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN FIRST_NAME
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN LAST_NAME
ELSE NULL
END SIM_CASE_CHARCOL,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN AGE
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE
ELSE NULL
END SIM_CASE_NUMCOL,
'123' * 10 IMPI_NUM1,
123 * '10' IMPI_NUM2
FROM
ODI_DEMO.SRC_CUSTOMER
INNER JOIN ODI_DEMO.SRC_CITY ON SRC_CITY.CITY_ID = SRC_CUSTOMER.CITY_ID
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
INNER JOIN (
SELECT COUNTRY_ID, COUNTRY, 'Europe' LOC, COUNT(DISTINCT REGION_ID) NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('France','Great Britain','Germany') GROUP BY COUNTRY_ID, COUNTRY
UNION
SELECT DISTINCT COUNTRY_ID, COUNTRY, 'Non-Europe' LOC, 0 NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('USA','Australia','Japan')
ORDER BY NR_OF_EURO_REG
) REG_COUNTRY ON SRC_REGION.COUNTRY_ID = REG_COUNTRY.COUNTRY_ID
WHERE
REG_COUNTRY.COUNTRY IN ('USA', 'France', 'Great Britain', 'Germany', 'Australia')
ORDER BY
LOC, COUNTRY
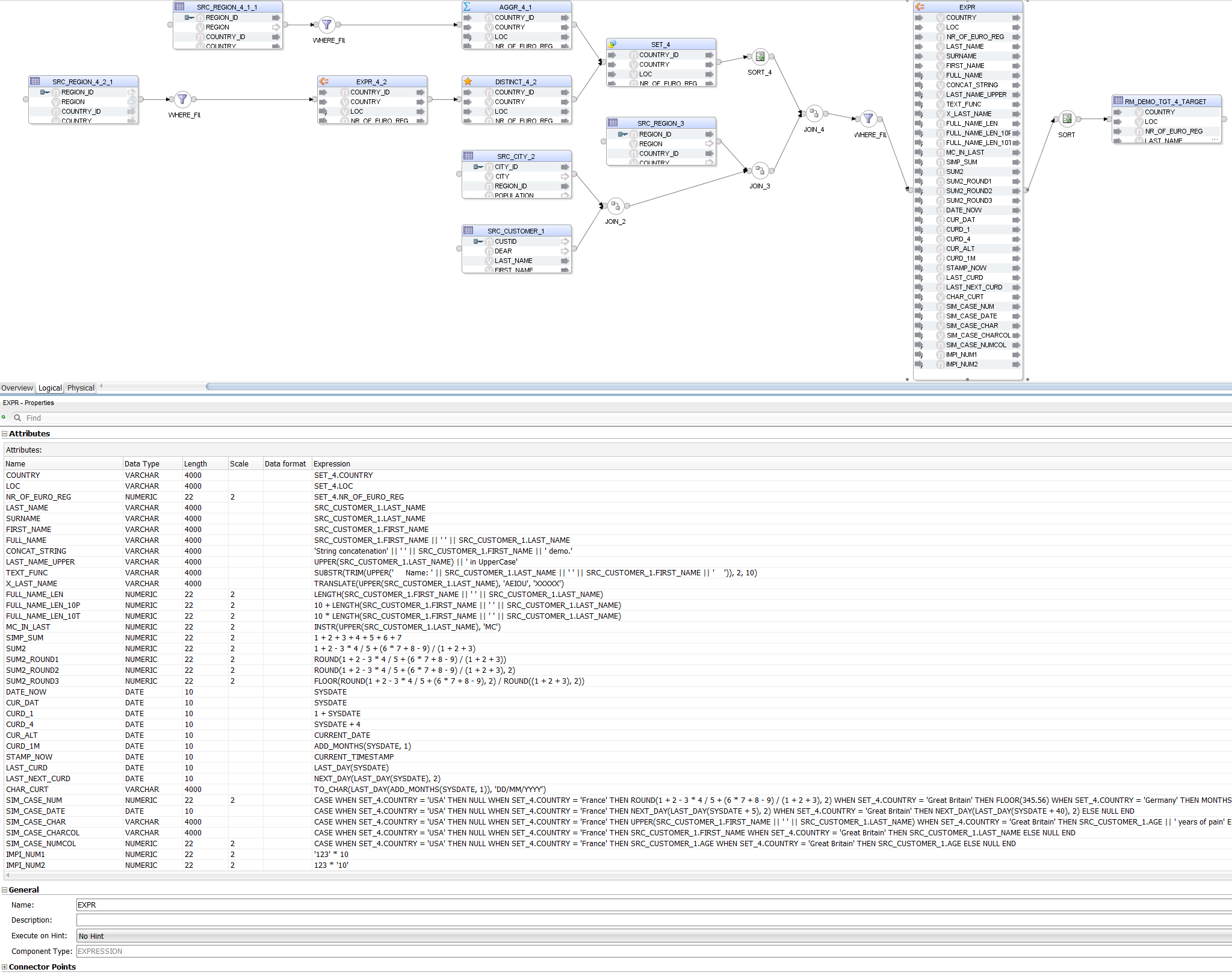
Notice that, apart from parsing the different Expressions, Sql2Odi also resolves data types:
1 + SYSDATEis correctly resolved as a DATE value whereasTO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURTis recognised as aVARCHARvalue - because of theTO_CHARfunction;LAST_NAMEandFIRST_NAMEare resolved asVARCHARvalues because that is their type in the source table;AGE || ' years of pain'is resolved as aVARCHARdespiteAGEbeing a numeric value - because of the concatenation operator;- More challenging is data type resolution for
CASEstatements, but those are handled based on the datatypes we encounter in theTHENandELSEparts of the statement.
Also notice that we have a UNION joiner for the two subqueries - that is translated into an ODI Set Component.
As we can see, Sql2Odi is capable of handling quite complex SELECT statements. Alas, that does not mean it can handle 100% of them - Oracle hierarchical queries, anything involving PIVOTs, the old Oracle (+) notation, the WITH statement - those are a few examples of constructs Sql2Odi, as of this writing, cannot yet handle.
Sql2Odi - what is under the hood?
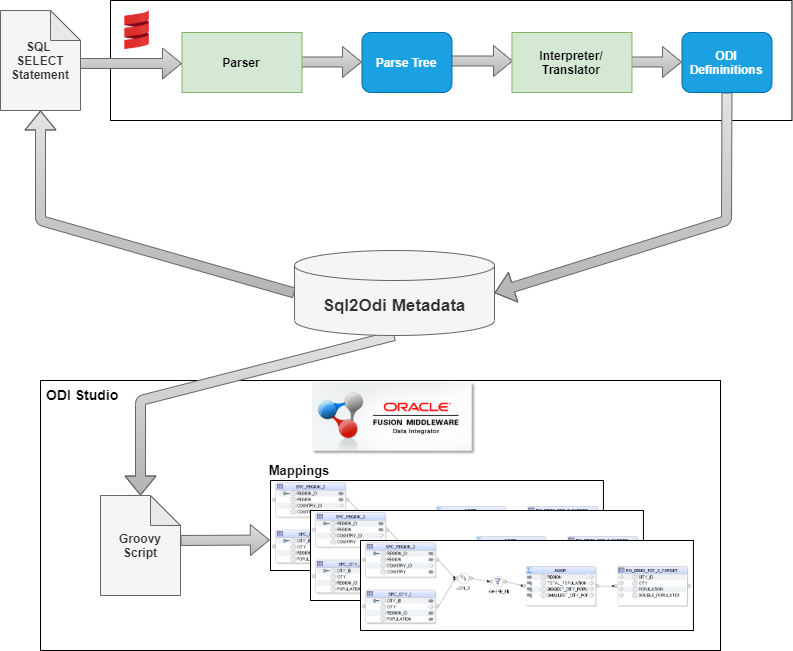
Scala's Combinator Parsing library was used for lexical and syntactic analysis. We went with a context-free grammar definition for the SELECT statement, because our goal was never to establish if a SELECT statement is 100% valid - only the RDBMS server can do that. Hence we start with the assumption that the SELECT statement is valid. An invalid SELECT statement, depending on the nature of the error, may or may not result in a parsing error.
For example, the Expression ADD_MONTHS(CUSTOMER.FIRST_NAME, 3) is obviously wrong but our parser assumes that the FIRST_NAME column is a DATE value.
Part of the parsing-translation process was also data type recognition. In the example above, the parser recognises that the function being used returns a datetime value. Therefore it concludes that the whole expression, regardless of what the input to that function is - a column, a constant or another complex Expression - will always be a DATE value.
The output of the Translator is a structured data value containing definitions for ODI Mapping Components and their joins. I chose JSON format but XML would have done the trick as well.
The ODI Mapping definitions are then read by a Groovy script from within ODI Studio and Mappings are generated one by one.
Mapping generation takes much longer than parsing. Parsing for a mapping is done in a split second whereas generating an ODI Mapping, depending on its size, can take a couple of seconds.
Conclusion
It is possible to convert SQL SELECT statements to ODI Mappings, even quite complex ones. This can make migrations from SQL-based legacy ETL tools to ODI much quicker, allows to refactor an SQL-based ETL prototype to ODI without having to implement the same data extraction and transformation logic twice.
Sql2Odi, Part One: Translate a simple SELECT statement into an ODI Mapping
We have developed a tool that translates complex SQL SELECT statements into ODI Mappings.

It was implemented using the Scala Parser Combinators library. We started by combining its Parser Generators into a context-free grammar to describe the Oracle SQL SELECT statement and… hang on, this blog post is not about impressing anyone with terminology. Let us start from the beginning, with the simple.
SQL-to-ODI translation - why bother?
ETL is most often prototyped with SQL statements. But, once shown that the data transformations we are after, work in SQL, we have do discard those SELECT statements and re-implement the same logic in ODI. Would it not be nice to refactor our SQL-based prototype into a first draft of ODI Mappings?
When migrating ETL logic from a legacy ETL system to ODI, it is likely that much of the legacy ETL logic will be presented in the form of a SELECT statement. If the number of those old mappings is in the tens or even hundreds, would we not welcome any opportunity to accelerate the migration process?
Bigger ETL implementations will typically have large sets of simple mappings following the same design template. If we want to replicate all tables in an OLTP Source schema to our Staging database, we could probably generate SELECT * FROM <source_table> statements for 100 source tables in an Excel spreadsheet in a minute. Creating that many ODI Mappings, no matter how simple, will take much longer than that. Do we not want to spend precious developer time on something more creative and challenging?
However, we do not always need a full-blown SQL parser and ODI Content generator for that. The attention-seeking introduction of this blog post is actually an extreme, complex example of ODI development acceleration. Simple ODI content generation can be done by simple means. There is no need for any form of SQL parsing if your mapping is based on a simple SELECT * FROM <source_table> statement. Now, for a moment let us forget about parsing and take a quick detour into the world of Groovy scripting, which is the first step towards generating ODI content.
Need to accelerate ODI development? Write a Groovy script!
I have been asked a couple of times about my favourite ODI feature. Without fail, I have always given the same reply - Groovy scripting!
In ODI Studio, from the main menu you navigate to Tools → Groovy, then choose New Script and write as much Groovy script as you please. It is that simple… sort of.

When scripting in Groovy, essentially the whole ODI SDK that the ODI Studio itself is based on, is at your disposal. So, in theory, everything you can do in ODI Studio, you can also script. You can design a Mapping, set up its Physical architecture (including IKM and LKM configuration), validate it and then create a scenario for it - all that with a Groovy script. It is a great tool to accelerate simple, repetitive build and migration tasks. On the flip side, the ODI SDK public API documentation is not very developer (especially beginner developer) friendly. Fortunately, Google is quite good at helping you with simpler questions you may have - Stackoverflow has quite a few ODI-related Groovy questions asked and answered. Also, if you like Rittman Mead as much as I do, ask them for the 2-day Advanced ODI 12c Bootcamp - you will not become an ODI scripting expert in two days but it will get you started.
It will never be quicker to script the creation of a mapping in Groovy than to create the same mapping in ODI Studio. However, if we are talking about many Mappings that are simple, hence easy to script, we can save a lot of time by involving Groovy.
We can create a script that generates mappings for all tables in a source schema to replicate them to our Staging schema. We can even add ETL Batch ID or Replication Date if required. But if we need more than that, we will either need to provide heaps of metadata to base the Mapping generation on, or need to better understand the SELECT statement. The SELECT statement will usually be the preferred option, because you can easily test it on the Source database.
Now, let us return to the original subject of SQL-to-ODI translation.
SQL-to-ODI translation - can it be simple?
Yes. If all your source extract SELECT statements come in the form of SELECT * FROM <source_table>, you could write a Regex expression to extract the table name, assuming that everything that comes after the FROM keyword is a single table name (i.e. no joins, no multiple tables). Then, if you can find a Data Store with the same name in an ODI Model, your script can add it into your Mapping and map the source columns to a Target table (mapping the columns by name or position). All that can be done with relative ease.
What if we add a filter to the SELECT statement? We can still parse it with Regex - everything between the FROM and WHERE keywords is a table name, everything after the WHERE keyword is a filter condition:
SELECT *
FROM <this is all table name>
WHERE <filter from here onwards>
That sounds simple enough and it is - sort of. You need to be careful when pinpointing the FROM and WHERE keywords - a simple text search will not do the trick. The two SELECT statements below are 100% valid, but:
- in the first one the
FROMis neither space- nor carriage return-separated from the SELECT expression(123), - the second one has two
FROMin it, where the first one is part of the column aliasWHERE_FROMand the second one initialises theFROMblock.
SELECT (123)FROM DUAL;
SELECT 'Milton Keynes' WHERE_FROM FROM DUAL;
Still, pinpointing the FROM and WHERE blocks is quite doable with a well written Regex expression (assuming no unions or subqueries).
Hopefully we do not need to pick the filter statement apart, because the ODI Filter Component accepts a single condition string.
Let us look at an example:
SELECT * FROM CUSTOMER
WHERE NAME IN (‘John’,’Paul’,’Peter’) AND SURNAME LIKE 'S%' AND AGE BETWEEN 25 and 85
In the WHERE clause above, we have a compound filter condition, consisting of three basic conditions joined with the AND keyword. If we would use the above in ODI, it will not be recognised as a valid ODI filter, because ODI requires column references to be in the form of TABLE_NAME.COLUMN_NAME (we could have an Expression, an Aggregate or other Mapping Component instead of a table name as well). Whereas the SQL statement above is perfectly valid, the filter requires adjustment before we can use it in ODI. Perhaps a text search/replace could do the trick but how do we know what to search for? And if we search and replace NAME with CUSTOMER.NAME, we will corrupt SURNAME.
You could write a Regex parser for this very particular filter condition to extract the column names from it. But if the filter changes to … AND AGE >= 25 AND AGE <= 85, we will have to change or extend the Regex string accordingly. No matter how good with Regex you are, you may have to give up here.
We could ask for the SELECT statement to be rewritten in an ODI-friendly form instead of trying to transform the filter condition in our script.
In addition to the above, if we have expressions (column references, constants, functions, CASE statements, etc.) in the SELECT part of the query, can we extract those with a script so we can add them to an ODI Mapping's Expression Component?
SELECT
123,
"string, with, commas,,,",
COALESCE(column1, ROUND(column2,2), column3, TRUNC(column4), column5),
...
When armed with just Regex, it will be very difficult. We cannot assume that any comma separates two expressions - many SQL functions have commas as part of their expression.
Transformation logic in the SELECT part of a query (i.e. anything beyond simple column references), joins, subqueries, unions - I would not try to attack that armed with Regex alone. In the context of SQL-to-ODI translation, I would deem such SELECT statements complex or non-trivial. That is where Combinator Parsing and more serious software engineering come into play. Let us discuss that in the Part Two of this blog post series.
Extending OAC with Map Backgrounds
One of the really powerful things in OAC is the simplicity with which you can create geographical insights using the Map visualisation. I say this as someone who has implemented maps in OBIEE several times and so know the challenges of MapBuilder and MapViewer all too well. It really is a case of chalk and cheese when you compare this to how easy things are in OAC! Well, things just got even better in OAC 5.9. With the introduction of Web Map Service (WMS) and Tiled Web Maps, we can now integrate custom backgrounds to overlay our layers onto. In this post, I will walk through the process of configuring WMS backgrounds and show how this may prove useful to OAC users with a use case based on openly available data sources.
Maps BackgroundBefore we look into these new Map Backgrounds...it's worth taking a moment to offer some background on Maps in OAC. For those of you know how things work, please skip ahead. For those who are new to mapping or who have used Map visualisations in OAC, but never stopped to consider how the data magically appears in your canvas, then here comes a brief guide:
For your data to be rendered on a map, you need three things:
- A Map Layer which defines the geometry of your data. The map layer must be presented in geoJSON format, which defines a series of points or polygon boundaries. The map layer must also include a key, which needs to match the key range in your data set...this is how OAC is able to interpret your data as relating to a specific point or space on the map layer.
- A Background Map, which is basically an image that sits behind the map layer and provides context to it. This would typically be an outline map of the world or it could have greater definition if that is helpful.
- A Data Set that includes a key attribute which relates to its geography. This may be as simple as a country code (or name) or it could be some form of surrogate or business key. When you use this data set to create a Map visualisation, you can allow OAC to determine which map layer to use (based on a comparison of the key in the data set with the configured keys in the available map layers) or you can specify the default layer to be used by setting the Location Details when preparing the data set.
Both Background Maps and Map Layers are configured within the OAC Console. Out of the box, you get a set of useful backgrounds and layers provided, but you are also able to configure your own custom layers and backgrounds. Once set up, they become available for users to select when they create a Map in their DV Canvas.
There's quite a lot to unpack here, including how you can source your geoJSON map layers (either from open sources or via SQL if the geometry data resides in your database), how to add custom layers, how to assign default layers and how to manage the join quality to ensure your visualisation is presenting the right data. Too much to get into here, but I may return to the subject in future - let me know if this would be useful to any of you!
Back to the Map Backgrounds...So, OAC provides you with three generic Background Maps out of the box:
- Oracle BI - a clean, silhouetted but coarse grained background map which provides differentiation of country boundaries
- Oracle Maps - a more detailed map which includes road networks, watercourses, national parks, place names etc.
- OpenStreetMaps - an open source background with similar detail to the Oracle Maps background, but a slightly more neutral style
The key thing for me, here, is that the options range from coarse grained to extreme detail, with not much in between. Plus, plotting data against a map that only shows physical infrastructure elements may not be relevant for every use case as it can easily complicate the picture and detract from the user experience.
What if I have a data set as per the one shown above (which gives me population and population growth for major towns and cities in England and Wales) and I want to present it in on a map, but in a way that will help me understand more than simply the geographical location? Well, the good news is that there are a growing number of open data map service resources that offer us a rich source for background maps. The better news is that from 5.9 onwards, we are now able to integrate these into our OAC instance and make them available as background maps. Specifically, we are able to integrate Web Map Services (WMS) and Tiled Web Maps.
WMS is a universal protocol introduced by the Open Geospatial Consortium and serves as a standard through which providers can make map details available and end user applications can request and consume the maps. The service consists of a number of different request types, among which the GetCapabilities request provides important details needed when integrating into OAC.
Taking my scenario as an example, and using the openly available UK Air Information Resource, we will look at how we can use this new feature to help us better understand the effects of population growth on air quality.
Understanding the GetCapabilities RequestAs mentioned before, the Background Maps are configured in the OAC Console, under the Maps option. Navigate to the Backgrounds tab and select the Add Background option. As you can see, we have two new options available to us (Web Map Service and Tiled Web Map).
Selecting the Web Map Service option presents us with the Add Background dialog box, where we can configure the map integration. You can see below that we need to provide a name for the background (this is the name that end users will identify the background by in DV) and an optional description. We also have some options that we need to derive from the map service, namely:
- URL - this is the URL for the server hosting the may service
- Version - this specifies the WMS version in use
- Coordinate Reference System - this is a standard value and cannot be modified
- Layers - the WMS service may support multiple layers, and here we can specify the layer(s) that we want to use, based on the layer name.
- Format - the type of image that will be rendered when using the background
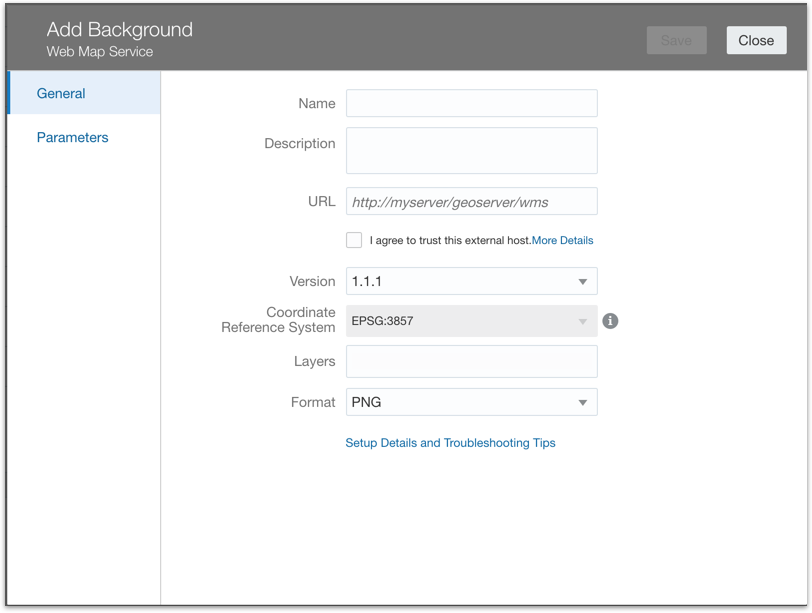
All of this information can be derived using the map services GetCapabilities request, which is an XML document that describes the definition of the service. Hopefully, your WMS provider will make the GetCapabilities easily available, but if not (and you know the URL for the host server) then you can pass the request=GetCapabilities parameter for the same result.
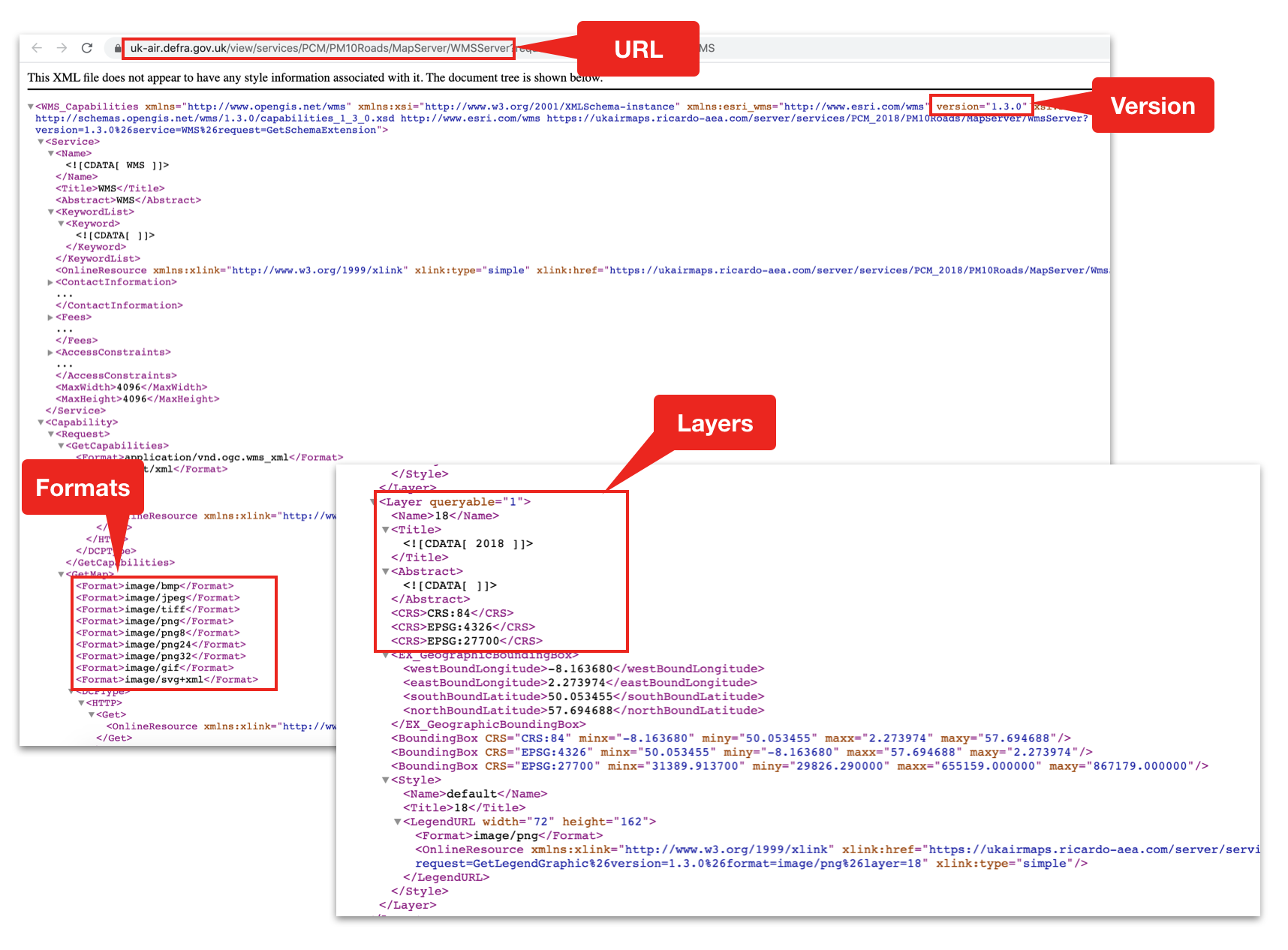
Once you have provided the required values, you must finally accept the trust statement (which will automatically add the host site to the Safe Domains list). After saving and a quick refresh, you should be able to inspect the new background and get a Preview. I've found it useful to do this up front, just to validate that the integration is working correctly.
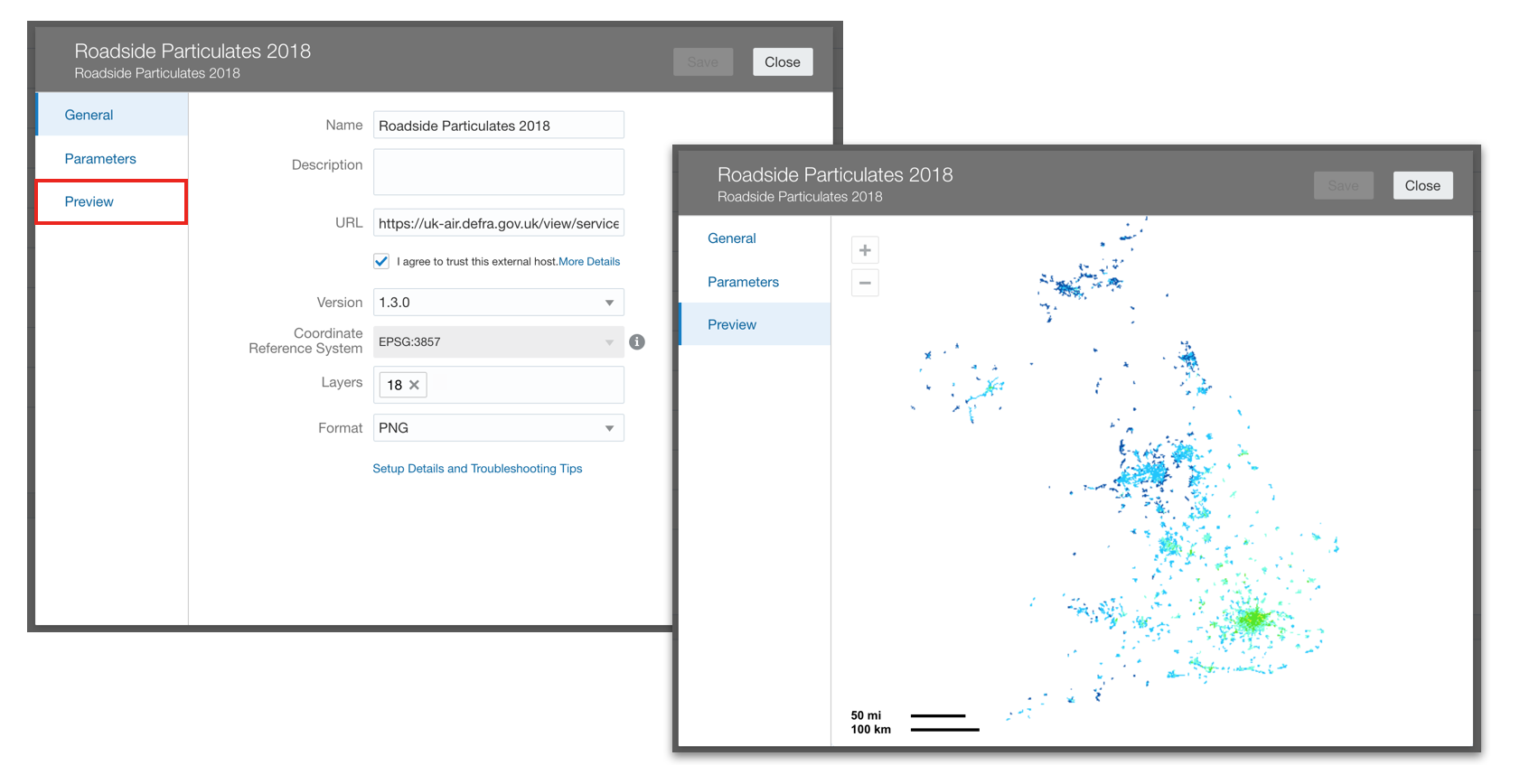
In my scenario, the WMS provides discrete layers for every year from 2001 to 2018. As my data set shows population growth between 2009 and 2019 and I want to see if there is any relationship between population growth and the changes in air quality over time, I have created three separate background maps showing snapshots at 2008, 2013 and 2018.
Now...once we've completed this set up (and assuming we have already created any custom Map Layers and have our Data Set to hand), we have everything we need to begin building some insights.
Using the Map Backgrounds in DVMy hypothesis is that population increase will result in greater use of the surrounding road networks and there should, therefore, be an increase in recorded roadside particulate levels. Obviously, there are other offsetting variables, such as the change in vehicles (cleaner technology, electric cars etc.) and societal changes towards a greener environment. I'm interested to learn something about the balance of these factors.
To start with, I will use the data set to identify the range of population growth of each town/city by way of a simple scatter graph. I have assigned colour based on a growth classification and, as well as plotting the growth %, I am using size to represent the base population. To save space, I am plotting data on the X Axis rather than the Y Axis. The end result looks like this:

Next, I create a map using the key element (Code), the Name of the town/city and the population growth measure. The appropriate map layer is selected (as I have already specified the default Location Details for this data set) and it is displayed on the Oracle BI background.
Now, instead of using the Oracle BI background, I am going to switch this to use the WMS based background I have just created...a simple case of navigating to the Map properties tab and selecting the appropriate background from the list.
This doesn't look great when viewing the entire data set, but I am more interested in looking at individual locations. I also want to see how the situation has changed over time. I therefore create two duplicates of the map and change the background to reference the 2013 and 2018 snapshot maps respectively (which, remember, simply pick up different layers within the hosted WMS). I increase the transparency of the Map Layer to 80% (so that I can better focus on the background map) and I switch the Use as Filter setting on my Scatter graph (so that I can use that to focus in on specific locations of interest). The resulting canvas looks something like this:
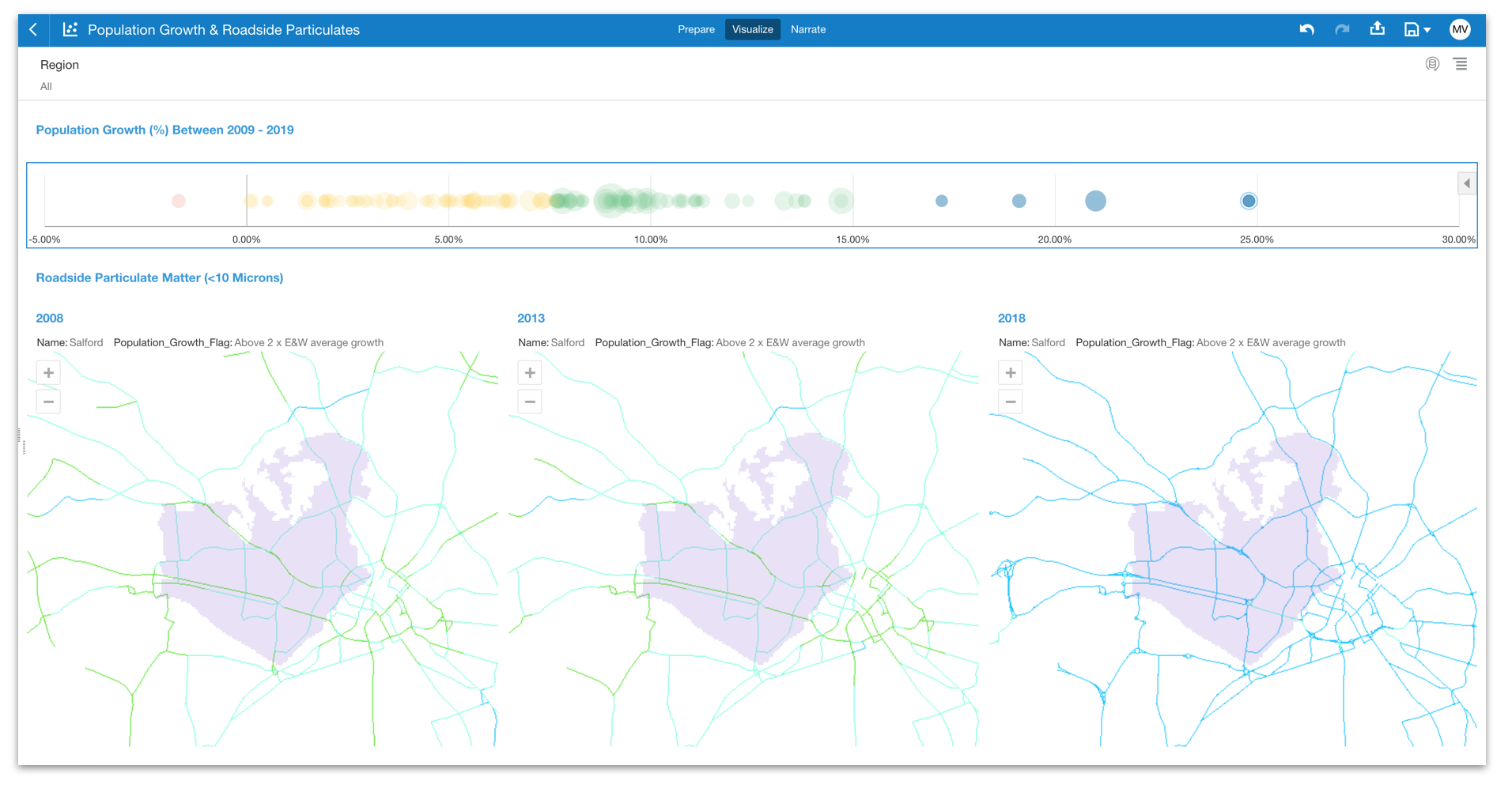 But...What Does It All Mean?
But...What Does It All Mean?I can definitely see a change in the roadside emissions, most markedly between 2013 and 2018, but I am missing something important. I have no idea what this change means. Without a legend, I am unable to say whether the analysis supports or contradicts my hypothesis...pretty but also pretty useless!
Luckily, the solution, once again, lies in the WMS service. Returning to the GetCapabilities definition, I can see that each layer includes a <LegendURL> tag which gives me the destination for the legend to the data. A quick check to make sure all layers are using the same legend (thankfully, they are) and an extra visualisation later (this time, an image that references the URL specified in the <LegendURL> tag), I get closer to understanding my data:
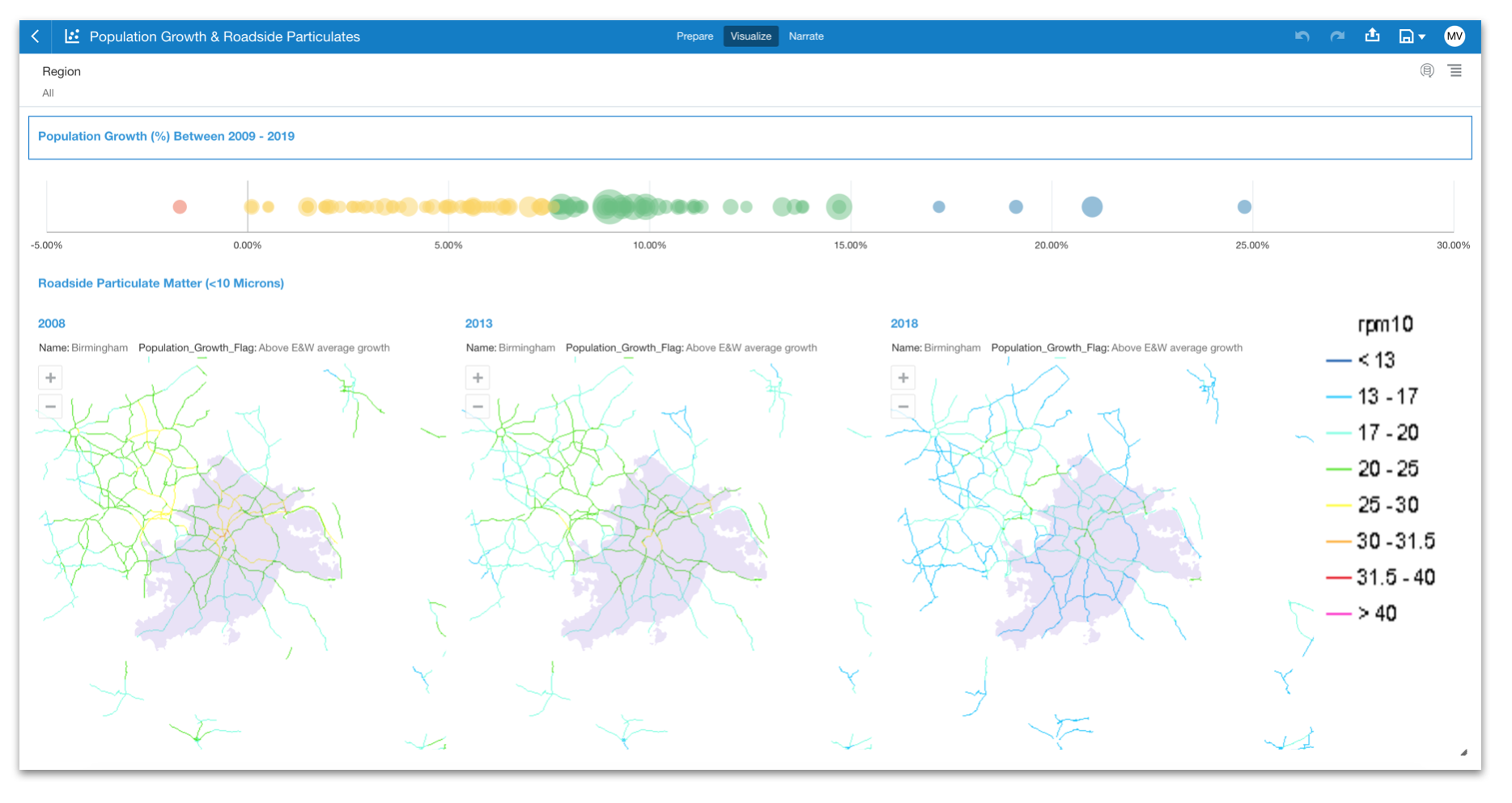
Quite pleasingly, it appears that, regardless of the rate of population growth or the location, there is a consistent reduction in recorded roadside particulate levels.
In SummaryAt this stage, it is probably worth saying that technically, it would have been possible to perform this same type of analysis in previous versions of OAC, as it has always been possible to create and overlay multiple layers within your Map visualisation. However, in practice, this particular use case would be impossible to achieve. It would involve carrying the data and the geometries for every single point of every single road appearing in the background map. That would be a lot of data, and even assuming we had it all available to us, it would be difficult to manage and definitely much, much slower to process than calling out to the WMS service and rendering the response images. Not to mention that the geoJSON file for the map layer would likely breach the size restrictions! Using the WMS integration saves us all this pain and opens up many more opportunities.
In fact, I can see some really powerful use cases for this new feature, as it takes the map background away from being a passive component of the Map visualisation and creates opportunities for it to become an active part of the insight process, enriching and adding relevant context to your existing data sets. Hopefully the use case I've presented here sparks your imagination and opens up some new ways of viewing data spatially within OAC.
Footnote: The examples shown above contain public sector information licensed under the Open Government Licence v2.0
Rittman Mead sponsoring RMOUG
After enjoying a successful 2020 in the North American data and analytics market, we’re excited to announce that we’re sponsoring Rocky Mountain Oracle Users Group (RMOUG) this year!
Running from 8th - 11th February, the agenda is jam packed with content including interactive workshops and technical sessions all presented by local and international Oracle product managers, partners and end users. There’ll be plenty of content covering everything from the newest developments in Oracle Analytics to database migrations. You can catch our CEO, Jon Mead at 11.30am (MST) on the 11th where he’ll be exploring how metadata can help you to understand and enhance user engagement. Don’t miss it!
We’ll be hosting a couple of break-out sessions (bring your own coffee) so if you want to chat Oracle Analytics, AI, ML, databases or anything in between then please feel free to virtually drop by and have a chat with one of the team.
Register here: https://events.bizzabo.com/TD2021/page/1611456/registration
OAC 5.9 - A Tour of the UX Enhancements
Now that we are nicely settled into 2021 (Happy New Year, by the way!), it's time to roll our sleeves up and take a look at the latest release from the Oracle Analytics team: Oracle Analytics Cloud 5.9. Whenever a new release arrives, there is often a clamour for the new functionality that it brings and whilst 5.9 introduces some interesting features that open up new opportunities for analytics users, this is not what caught my immediate attention.
I will take a look at the new features in due course, but in unpacking 5.9, I was first struck by the enhancements in user experience. UX - a tricky to pinpoint combination of efficiency, convenience, intuitiveness, comfort, productivity and emotion - is often the biggest driver of how well a system is adopted. So, it is essential that these things don't get overlooked and it's good to see that they have not been in 5.9. Even though they might seem trivial when considered in isolation, sometimes...
...it's the small things that make a big differenceIf, like me, you've spent some time working with DV, you've probably spent a portion of this time watching the blue progress bar jump to 90% and then waiting for the processing to complete and the visualisation to render. You've also probably been caught out once or twice not noticing the blue bar and thinking that the visualisation in focus is displaying the refreshed results. This can be frustrating and so I was pleased to see that this has been updated in 5.9. The blue bar has been assigned to the dustbin and replaced by a spinning wheel which appears when you roll your mouse over a particular visualisation. More importantly, during refresh, the stale visualisation is no longer shown and the visualisation is only displayed when the refresh has completed. To me, this is a more elegant approach for a couple of reasons: firstly, it removes the trap described above - you can be confident that when you see a visualisation displayed, you are looking at the latest, freshest output. Secondly, if you have multiple visualisations on your canvas, your attention is actively drawn to visualisations on completion, allowing users to focus in on what is immediately available, rather than waiting until all visualisation are refreshed. Confusion reduced, efficiency increased.
It's always important that the interface is as clean and simple as possible and, when space is at a premium, maximising the area for building and working with your visualisations (aka the canvas) is essential. This has been addressed in 5.9 by a really simple change: in the left-hand panel, the Data, Visualizations & Analytics tabs have been switched from a vertical layout to a horizontal layout, now appearing at the top, above the search bar. Add this to the simplified header (without the Oracle Analytics header and the Project header minimised) and the result is quite noticeable. Again, nothing mind-blowing, but the impact is significant, creating a much cleaner interface with much more of the real estate dedicated to the important stuff.
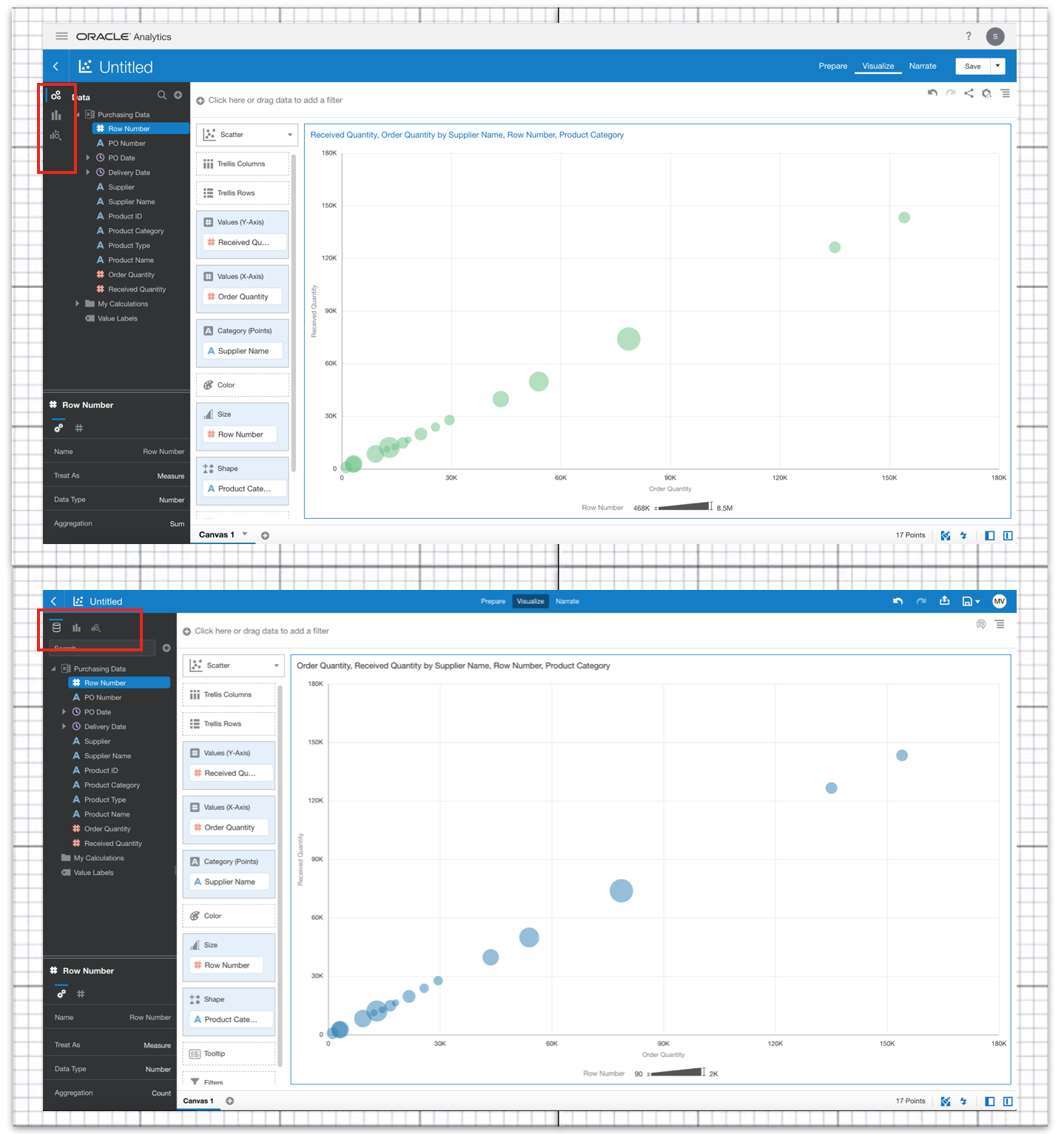
Elsewhere, there are two interesting enhancements as to how we can interact with the Canvas. The first involves sorting data within a visualisation. There is a minor cosmetic change to the way the sort options are presented, with the measures and attributes now being displayed in a nested menu structure rather than a single list. We are still able to perform nested attribute sort ordering or sorting on measure values, but the new menu structure is cleaner and more intuitive, as it also depicts the grammar assignment (colour, size, shape etc.) for each data element. More importantly, as you can see in the screenshot below, we are also now able to explicitly remove sort ordering by selecting None. This removes any default sorting applied to the data when it is added to the canvas.
The second revolves around filtering. You will be familiar with the way that canvas level filters are assigned at the top of the Canvas (via the filter bar), whilst it is also possible to apply filters discretely within any given visualisation (within the Filters assignment). These visualisation level filters get applied in addition to any canvas level filters. However, up until now, the filters needed to be created independently of each other and if you wanted to switch from a canvas level filter to a visualisation level filter (or vice versa), frustratingly, you had to remove and recreate the filters. This has been addressed in 5.9, with filters now being interchangeable, simply be dragging and dropping a created filter from one area to the other. Another nice efficiency saving!
There's not too much to report in terms of new visualisations in 5.9, but we do see the addition of a new area chart option. Previously, we only had two options: Area (pictured below) and 100% Area. Now...the Area option was always confusing to me as it actually stacked measure values, making the Y axis a cumulative scale and not an absolute one. I always found this made it difficult to compare measure values and it was relatively easy to misinterpret the scale. This has been addressed through the addition of the new option (named Area). This allows us to plot our data on a single value scale (Y axis), showing the absolute values as opposed to the cumulative values stacked on top of each other. Conveniently, the areas are displayed with some transparency, as they are overlayed on top of each other and, as normal, these settings can be manipulated through the Properties menu. The old Area visualisation remains, but has been (appropriately) renamed as Stacked Area and the 100% Area option also remains unaffected.
One of the major strengths within DV is the ease with which data can be acquired and loaded, with preparation actions being defined and applied to the data on its journey into the system. The ability to clean source data has been made a little simpler in 5.9 with the addition of a TRIM function which allows you to eliminate any leading or trailing spaces from source data elements. Interestingly, I hit exactly this issue on my current project and, whilst it was simple enough for me to create a custom transformation, I can see how achieving the same result with a single mouse click will be very useful to many self-service users.
Now, as much as we rail against the thought of users moving data and insight outside of the platform, it is an inevitability that we've all come to accept. It's therefore interesting to see that the classic data download limits (i.e. Enterprise Analysis & Dashboards) has been increased (2m rows for 2-12 OCPU's or 4m rows for 16-52 OCPU's) for raw downloads and for formatted downloads (200k rows for 2-12 OCPU's or 4ook rows for 16-52 OCPU's). There are also some nice improvements to the share/export feature in 5.9, with the outputs to Powerpoint, PDF and Image now being much cleaner. Where previously, the formatting of the exported outputs was a little clunky and often required manual adjustment, in 5.9 the rendered output is much more closely aligned to what you see on your screen when working in DV. Aspect ratios are respected and the end result is all the better for it!
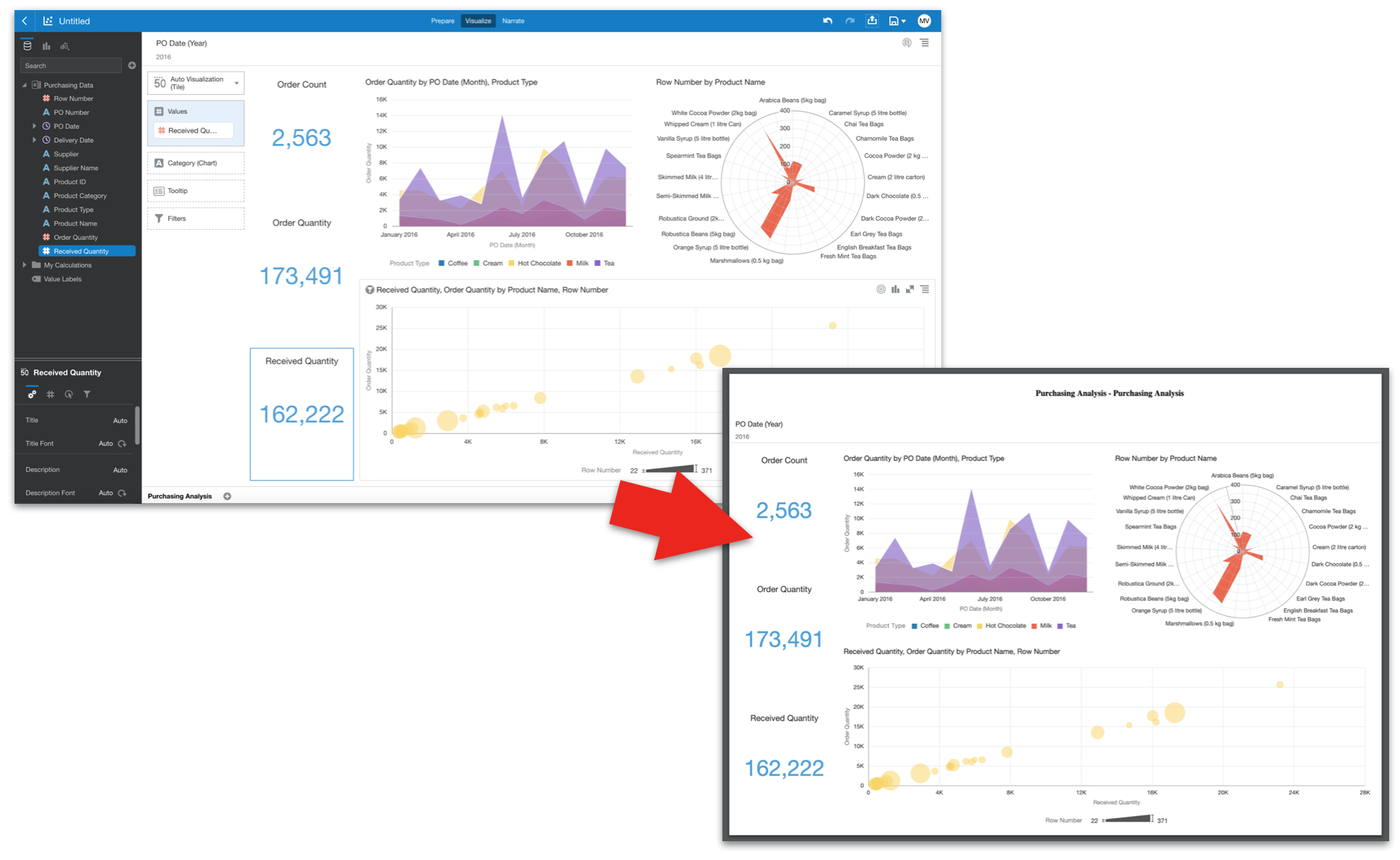
Finally (for now, at least), 5.9 brings us greatly increased flexibility over the ways we can present geographical insights with the inclusion of Web Map Services and XYZ Tiled Web Maps as sources for your Background Maps. This allows you to configure map backgrounds based on integrations with openly available services. Configuration is a relatively simple process and once created the new backgrounds are immediately available for your self-service user community to grab and create map layers over as soon as configured.
In summary, I can definitely see how the enhancements described above will make OAC 5.9 a cleaner, more intuitive platform allowing users to be that little bit more efficient in their work. When aggregated, I think the cumulative effect becomes quite measurable.
Next time, I'll look into these new background map integrations in more detail and also explore the other new features that arrive in 5.9, including some new data preparation actions, assistance in understanding machine learning models and more.
Using the Go-URL in OAS
The OBIEE Go-URL functionality is widely used and it's deprecation in OAS is causing issues for companies wishing to upgrade to OAS.
This is a feature of OBIEE that allows a report to be accessed directly from a URL, enabling links from other applications - often with optional parameters passed through to filter the report - and usually bypassing the login screen by including user credentials within the URL parameters.
Typically a single user-id is used for Go-URL access to OBIEE reports thus avoiding the need to either enter/detect user details or to provide login credentials for users who would not login to OBIEE directly.
With the first release of OAS, Oracle have announced that the Go URL functionality is being deprecated and may be removed in a future release. Also, since OBIEE 12.2.1.3, the advent of the combined bi security login screen for both Analytics and DV has meant the NQUser and NQPassword parameters no longer work, so it is not possible to specify a user for the Go URL and hence it cannot login.
There are currently two scenarios under which the Go-URL does work in OAS:
-
If full Single Sign-on to OAS has been implemented - via Oracle Access Manager or Apache, currently the only recognised methods for SSO in OAS - then the Go-URL will work under the user-id that SSO signs in under. In other words, the user credential parameters in the URL are ignored, the user logs in automatically under their credentials and the requested report displays as normal.
However this is often not appropriate - if users are clicking on Go-URL links outside the scope of the SSO environment, for instance connecting via the internet or from other networks within the company LAN where SSO could not operate. Also if reports are designed to work under a specific user, perhaps with special security rules, a users own security levels may result in different data appearing in a report.
- Disable the lightweight SSO option in OAS. This separates the security for Analytics and DV. For Analytics this returns to the classic login screen and the NQUser and NQPassword parameters on the Go-URL work correctly, but this causes issues for DV making it virtually unusable. This is only really an option if you do not want to use DV in your implementation of OAS.
There is however a third option we have discovered which uses the Single Sign-On approach, but without the need to actually detect user credentials via an SSO service. Instead a specific user-id can be provided, just like the NQUser parameter in the Go URL.
Instead of the Go URL passing the NQUser and NQPassword parameters, Apache can be used to re-direct access to OAS, providing the user-id to login with during the re-direct. The effect is that the Go URL will still display the same report output whilst logging in with the same user-id, albeit supplied by Apache rather than the NQUser parameter.
This works by using the Single-Sign-On configuration between Apache and OAS.
In a normal SSO configuration, Apache would authenticate users via a standard SSO service, for example, Kerberos, and once the user has passed authentication, redirect the URL to OAS, providing the user credentials as request-headers, so that OAS can automatically login the user in, bypassing the login screen.
The Oracle document ID 2707401.1 explains this process in detail.
We can however ignore the SSO authentication within Apache and instead hard-code the User-id we want to login to OAS with. Apache will still send this user-id in the request-header to OAS, which in turn will recognise it as a pre-authenticated user and log the session in. In the case of a Go URL, the rest of the URL which points to a report or dashboard will continue to process as normal, displaying it to the user.
The user is totally unaware of the difference - they click on a link and see a report in OAS just as they did in OBIEE.
Just as with the Go URL there are security implications of this. The user-id and password are no longer sent in plain text in the URL, which is an improvement, but calling the URL will automatically login you into OAS. if you just use the core URL of http://oas-server:port/analytics, you will be logged in to OAS and end up at the home screen, without any user/password challenge.
It is important therefore to restrict the permissions and privileges of this hard-coded user so it can only access the reports/data it needs to and cannot create new content, access other subject areas etc. Using the Apache configuration, OAS can be tied down so that just the /analytics URL can be opened for this, so no access can be given to /dv, /xmlpserver or any other area of OAS unless explicitly required.
By using Apache to control access to OAS you create a separate port to call OAS on for the Go-URL. This means the port you installed OAS with (e.g. 9502/9503) will remain as the main port for logging into OAS via the login screen - users manually connecting to OAS for analytics, DV and all the other functionality, should continue to use this port. These connections will not go via Apache.
The Go-URL will use the port provided by Apache - in the instructions below I’ve set this up as port 9603 - and Apache will re-direct the user seamlessly to OAS’s main port. Apache can also be configured to use SSL certificates, and if installed on the same server as OAS, the same certificates as OAS. In this example I’m not using SSL, but the instructions for doing so are included.
Assuming you have already OAS installed, below are the steps to install and configure Apache to act as the “SSO” front-end for the Go-URL. The instructions below were carried out on an Oracle Enterprise Linux 7.8 server - other versions of Linux or using Windows will be slightly different.
Start by installing Apache HTTP ServerAs the root user, use yum to download and install Apache and the required SSL and SSO plug-ins:
yum -y install httpd mod_ssl mod_auth_kerb mod_auth_token
Then enable and start Apache:
systemctl enable httpd.service systemctl start httpd.serviceNext enable Apache to connect to the network and allow access on port 9603. In this case I’ve installed policycoreutils to get the semanage command as I have SELinux enabled.
yum -y install policycoreutils-python
/usr/sbin/setsebool -P httpd_can_network_connect 1
semanage port -a -t http_port_t -p tcp 9603
semanage port -l | grep httpThe final command above confirms port 9603 is now available:

Next open the firewall port for 9603:
firewall-cmd --zone=public --add-port=9603/tcp --permanent service
firewalld stop service
firewalld start
systemctl restart httpd.serviceNow Apache is is installed, we can configure it. Edit the file /etc/httpd/conf/httpd.conf
Set the Listen port and, if SSL is required, add the SSL virtual host properties with the correct server, port and SSL certificate file values (I’ve included the SSL virtual host in httpd.conf, but it could reside in it’s usual place in ssl.conf instead)
Listen 9603
<VirtualHost oasvm3.local.com:9603>
ErrorLog logs/ssl_error_log
TransferLog logs/ssl_access_log
ServerName oasvm3.local.com
SSLEngine on
SSLProxyEngine on
SSLCertificateFile /u01/oas55/ssl/certificate.crt
SSLCertificateKeyFile /u01/oas55/ssl/certificate.key
SSLCertificateChainFile /u01/oas55/ssl/certificate_chain.pem
SSLCACertificateFile /u01/oas55/ssl/ca_certificate.crt
SSLProxyCACertificateFile /u01/oas55/ssl/ca_certificate.crt
RequestHeader set WL-Proxy-SSL "true"
RequestHeader set IS_SSL "ssl"
RewriteEngine On
RewriteOptions Inherit
ProxyPreserveHost On
</VirtualHost>save and close, then restart apache:
systemctl restart httpd.service
Then try the Apache URL in a Browser: http://oasvm3.local.com:9603 (or https for ssl)
if using SSL check for the padlock icon in the address bar.
Configure Apache for OASRe-open the httpd.conf file and locate the line:
#ServerName www.example.com:80below this add the following lines - these are typical recommended settings for OAS
###### Various default settings ######
#
# Timeout: The number of seconds before receives and sends time out.
#
Timeout 6000
#
# KeepAlive: Whether or not to allow persistent connections (more than
# one request per connection). Set to "Off" to deactivate.
#
KeepAlive On
#
# MaxKeepAliveRequests: The maximum number of requests to allow
# during a persistent connection. Set to 0 to allow an unlimited amount.
# We recommend you leave this number high, for maximum performance.
#
MaxKeepAliveRequests 0
#
# KeepAliveTimeout: Number of seconds to wait for the next request from
# the same client on the same connection.
#
KeepAliveTimeout 60
#
#####################################Now add the following lines to the end of the file, altering the OAS URLs appropriately. The ProxyPass URLs must be the original SSL or Non-SSL OAS URLs.
Define GoUser reportuser
RewriteEngine On Proxy
PreserveHost On
# Protected Resources
<Location "/analytics">
ProxyPass "http://oasvm3.local.com:9502/analytics"
ProxyPassReverse "/analytics"
#SSLRequireSSL
RequestHeader unset Authorization
RequestHeader set OAM_REMOTE_USER ${GoUser}
RequestHeader set iv-user ${GoUser}
RequestHeader set SM_USER ${GoUser}
</Location>
ProxyErrorOverride Off
# Unprotected Resources
<Location "/bi-security-login">
ProxyPass "http://oasvm3.local.com:9502/bi-security-login"
ProxyPassReverse "/bi-security-login"
</Location>
The first line defines the user which will login to OAS, in this case I’ve created a user called ‘reportuser’. This is then substituted into the request headers below.
Ideally this user should exist in the provider used for authentication in Weblogic - so that any security groups can be picked up to control this user's access with OAS.
Note the SSLRequireSSL is hashed out, the hash must be removed if SSL is required.
save and close, then restart Apache:
systemctl restart httpd.service
To enable Weblogic to recognise SSO tokens to Apache we use the OAM Identity Asserter.
Login to the Weblogic admin console, Navigate to Security Realms → myrealm → Providers, then Click Lock & Edit, then click New.
Click New. Enter a name and choose OAMIdentityAsserter as the type.
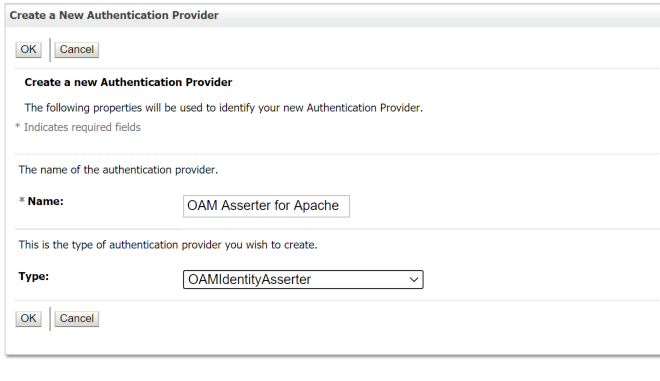
Click OK to add the provider:
Click on the new OAM Asserter provider to edit it. Change the Control Flag to REQUIRED & click Save. The remaining default settings are fine.
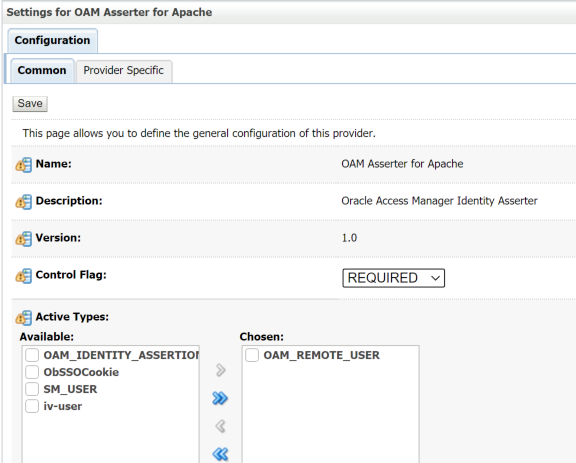
Return to the providers screen, click Reorder and move the OAM Asserter so it is second in the list below the main user directory, in this case PaulsAD is the main active directory authenticator
This next step isn’t strictly necessary - the Weblogic Plug-in is required to allow access to Data Visualizer and if you have no intention of allowing access to DV via Apache, this step can be skipped.
The Weblogic Plug-in needs enabling in three locations.
From the Domain Structure window click on bi
Go to the Web Applications tab
Scroll down to the WebLogic Plugin Enabled option and check it. then click Save.

From the Domain Structure window expand Environment and click on Servers. Click on bi_server1 in the Configuration tab.
Scroll down the General, click on the Advanced link, then locate the WebLogic Plug-In Enabled option and set it to ‘yes’. Click save.
From the Domain Structure window click on Clusters. Click on bi_cluster
Again in the General tab click on Advanced then set the WebLogic Plug-In Enabled option to ‘yes’. Click save.

All changes are now complete. Click Activate Changes.

A full stop and restart of Weblogic & OAS is required under the oracle user:
/u01/oas55/config/domains/bi/bitools/bin/stop.sh
/u01/oas55/config/domains/bi/bitools/bin/start.shFor this method of accessing OAS to work, the internal lightweight SSO must be enabled. It will be enabled by default, but if it has been disabled, for example to make the Go-URL work, then re-enable it:
Stop OAS, open the WLST command line:
cd /u01/oas55/product/oracle_common/common/bin ./wlst.sh
Re-enable SSO (alter the domain path to suit your environment)
wls:/offline> enableBISingleSignOn('/u01/oas55/config/domains/bi','/bi-security-login/logout?redirect=/dv');
wls:/offline> exit();Then restart OBIEE to reflect the changes.
The Apache configuration is now complete and you should be able to login to OAS on the Apache URL, e.g. http://oasvm3.local.com:9603/analytics
The SSO configuration should automatically log you in under the user defined in the apache configuration above:
The Original OAS URL remains on port 9503 and will take you to the normal login screen:
Note than when you login via the Apache you can’t sign-out! You can click the sign-out link, but the SSO process will simply login you back in again rather than displaying the login screen. To login normally close the browser and reopen with the standard OAS URL.
Apache Log filesIf you have any issues with the above, there are five log files for Apache you can use investigate whats going on.
/var/log/audit/audit.log Contains SELinux issues
/var/log/messages Contains general activity messages
/var/log/httpd/error_log Contains errors generated by Apache,including some SSL and Kerberos messages
/var/log/httpd/ssl_error_log Contains SSL errors generated by Apache
/var/log/httpd/ssl_access_log Contains messages related to users connecting over SSL
The logging level in the error_log file is governed by the LogLevel setting in /etc/httpd/conf/httpd.conf This is normally be set to ‘warn’, but can be set to debug to display detailed messages.
 Testing the Go URL
Testing the Go URL
With Apache/SSO now enabled, the Go URL can be used:
http://oasvm3.local.com:9603/analytics/saw.dll?Go&Path=%2Fshared%2FPipeline QuickAnalytics%2FPipeline%2FSales Pipeline-Charts&locale=en-en&lang=en
Note that if the Go URL includes the NQUser and NQPassword parameters, they will be ignored.
Alternatively the Dashboard parameter can be used to take a user fully into OAS to view a dashboard:
http://oasvm3.local.com:9603/analytics/saw.dll?dashboard&PortalPath=%2Fshared%2FPipeline QuickAnalytics%2F_portal%2FSales EffectivenessAn important point here is that the user is now logged into OAS and can access other content. As mentioned earlier, the user used for Go URL access should have their permissions and privileges tightly controlled to limit access to just what it required.
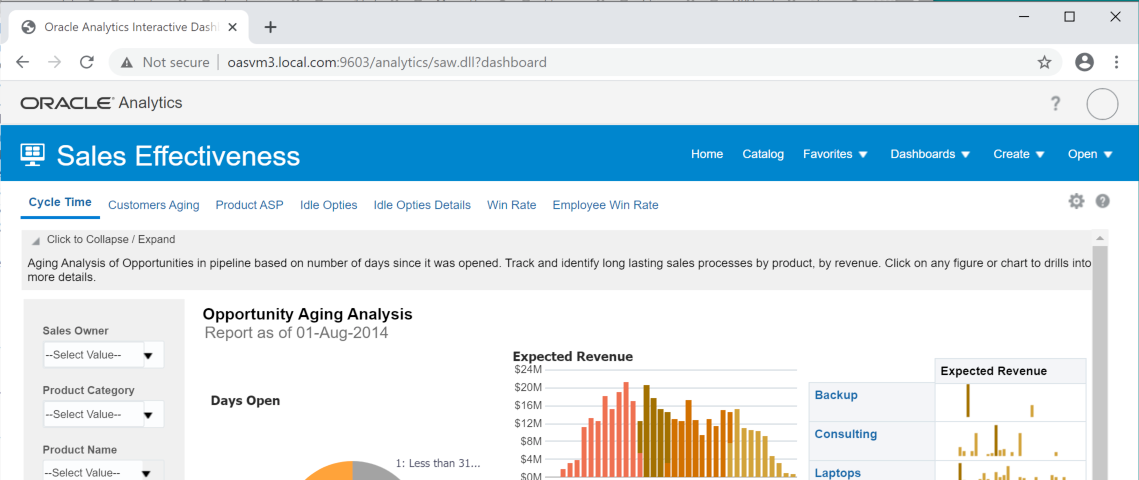 Accessing other areas of OAS
Accessing other areas of OAS
The instructions above only provide access to the core /analytics functionality via the Apache SSO URL. Other areas of OAS, such as /dv or /xmlpserver are not enabled:
If these are required the location entries must be added to the httpd.conf file and Apache restarted.
The full list locations can be found in the Oracle doc mentioned earlier, and includes protected and unprotected locations (as some must be visible prior to logging into OAS, e.g. the bi-security-login URL). As an example, here is the location required to enable DV:
<Location "/dv">
ProxyPass "http://oasvm3.local.com:9502/dv"
ProxyPassReverse "/dv"
#SSLRequireSSL
RequestHeader unset Authorization
RequestHeader set OAM_REMOTE_USER
${GoUser} RequestHeader set iv-user
${GoUser} RequestHeader set SM_USER
${GoUser}
</Location>Thats it, your now ready to use the Go-URL with the Apache URL and not include the NQUser/NQPassword parameters.
This solution is not ideal and does have security implications you must take care of, although it does avoid the user/password appearing in the URL, which is a definite positive.
One downside of this is that you can’t use multiple user-ids - all the Go URL’s will connect with the same user, it is not possible (well we’ve not found a way yet) to allow different Go URLs to connect with different user-ids. Apache will only allow one redirect to /analytics on the main listen port.
Enjoy!
Analysing Social Media Activity with ADW and OAC

Yesterday I wrote a series of tweets talking about my Twitter activity analysis with Oracle's Autonomous Database and Oracle Analytics Cloud. Since the tweet became popular and I didn't share the steps, I thought a blog post should follow, so... here we are!
[1/N]
I wanted to analyse my Social Media data.
I exported my @Twitter data and analysed with the #OracleText in the #OracleAutonomousDatabase @OracleDatabase and @OracleAnalytics Cloud
Starting from the easy… which is the tweet with most likes?
hint: Becoming @oracleace #ACED! pic.twitter.com/gUQR0Ur7k7
There are many ways that you can get data from Twitter. For the sake of my exercise I requested a dump from my data from the Twitter website. You can request the same following these instructions.
Once the data is ready, you'll receive a mail or a notification and you'll be able to download the related zip file named twitter-YYYY-MM-DD-hashed_string.zip.
Once unzipped you'll see two folders:
assetscontaining files you attached in your tweets (mostly images)datawhere the actual interesting information is.

Within the data folder I concentrated on the tweet.js file which contains the tweet information. There are other interesting files such as followers.js or like.js but I didn't include those datasets in my analysis as of now.
Warning: the tweet.js dataset contains only the tweets written by you. It doesn't contain all people tagging you in a tweet or replies to your tweets.
The Your archive.html file allows you to browse the content on the folder from a web browser
 Importing Data into ADW with SQL Developer Web
Importing Data into ADW with SQL Developer WebThe next step in my analysis is to import the data into the Autonomous Data Warehouse. For this task, I used SQLDeveloper Web, available by default in ADW, which has a powerful utility to import JSON documents as rows in a relational table. Jeff Smith's post covers the process in detail.
Unfortunately when trying to import into ADW the file tweet.js I encountered an error due to the fact that the file itself is not a pure JSON file, pretty clear if you check the file itself
window.YTD.tweet.part0 = [ {
"tweet" : {
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
.....
"lang" : "en"
}
},
....
{
"tweet" : {
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
.....
"lang" : "en"
}
}
]The first item to remove from our file is the window.YTD.tweet.part0 = prefix. I believe this is due to the pagination of the results, but it clearly screws up the JSON formatting.
Once removed I could parse the tweet.js file with SQLDeveloper Web, but the table definition proposed had only one column with containing the whole TWEET JSON document.
At this point, I could either accept this and do further processing using Oracle's SQL JSON parsing functionality or slightly change the shape of the file to be ingested correctly and I opted for the second.
When importing JSON documents into rows, SQLDeveloper Web analyses only the first level or attributes in the document itself. In the case of our tweet.js file was something like
{
"tweet" : {
...
}
},
{
"tweet" : {
...
}
},The first level parsed by SQL Developer Web was correctly only extracting the tweet element and proposing a CLOB (JSON) column to store it. But I wanted the content of the tweet to be parsed. I ended up removing the first layer by substituting in the file any occurrence of },{ "tweet" : { with a simple comma and removing the initial and final parenthesis.
The file now looks like the following
[ {
"id" : "279908827007180800",
"created_at" : "Sat Dec 15 11:20:39 +0000 2012",
"full_text" : "Finally at home after #christmasparty... Looooong travel!",
"lang" : "en"
...
}
,{
"id" : "276794944394498048",
"created_at" : "Thu Dec 06 21:07:12 +0000 2012",
"full_text" : "@mRainey will you be there next week too? Enjoy uk and visit #italy if you can!",
"lang" : "en",
...
}
...
}]We can now parse the file with SQL Developer Web, and the output correctly identifies all the first level entities in the JSON document.
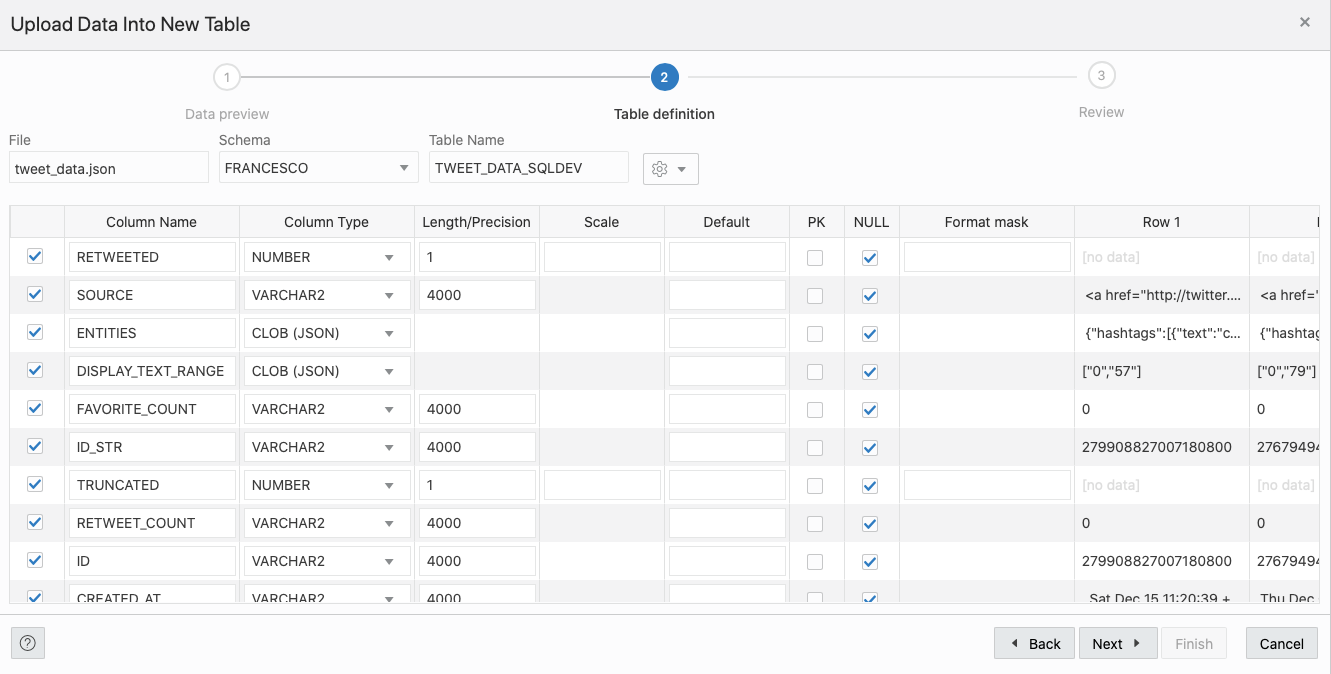
Few more clicks and we have our table FRANCESCO.TWEET_DATA_SQLDEV populated automagically!
Note: The whole process above could be implemented and automated in several different ways, the aim of the blog post is only to demonstrate the feasibility of the analysis.
Text Tokenization with Oracle TextThe Tweet's FULL_TEXT column tokenization is done in the Oracle Database, you can see the full process described by the following video produced by the Oracle Analytics PM team.
If you prefer a short version of it, here it is: I basically created the following index
CREATE INDEX "FRANCESCO"."TWITTER_TWEET_IDX" ON "FRANCESCO"."TWEET_DATA_SQLDEV" ("FULL_TEXT") INDEXTYPE IS "CTXSYS"."CONTEXT";The INDEXTYPE IS "CTXSYS"."CONTEXT" creates an index using Oracle Text. A more accurate description of the procedure can be found in OracleBase's post.
Once the index is created, we can see some new tables appearing with the name DR$INDEX_NAME$LETTER with
$DR$being a fixed prefixINDEX_NAMEthe name of the indexLETTERa single letter betweenI,K,N,U,Rwhich meaning can be found in this Document
For the purpose of our analysis, we'll focus on the DR$TWITTER_TWEET_IDX$I table which contains the tokens of our FULL_TEXT column.
But the token by itself is not very useful, we need to match the token with the Tweet's ID to be able to provide meaningful analysis. Again, this is covered nicely by another video created by the Oracle Analytics PM team.
In order to associate the Token with the original Tweet we can use again the power of Oracle Text and the Index created above with the following query
SELECT
full_text,
score(1) AS text_score,
token_text,
a.id
FROM
tweet_data_sqldev a,
(
SELECT DISTINCT
token_text
FROM
dr$twitter_tweet_idx$i
)
WHERE
contains(a.FULL_TEXT, '/' || token_text, 1) > 0Again for more info about Oracle Text's CONTAINS function please refer to the relevant documentation.
I physicalized the output of the above query in a table ( TWEET_TOKENS), which contains the TOKEN_TEXT together with the Tweet's ID so we can now join this table with the original one containing the list of Tweets in Oracle Analytics Cloud.
Note: One of the next versions of Oracle Analytics Cloud will provide the Tokenization as step of a DataFlow within the Database Analytics options! You'll be able to tokenize your strings without leaving OAC.
 Analysis of the Data in Oracle Analytics Cloud
Analysis of the Data in Oracle Analytics CloudIf you're a frequent blog reader, this is probably the easiest part. I just had to:
- Create a connection to my Autonomous DataWarehouse by using the wallet file.
- Create the two datasources: one for
TWEET_DATA_SQLDEVand another forTWEET_TOKENS - Create a project and include both Datasources
Once in the project, the first visualization is about the most "liked" tweet... no surprise is when I become Oracle Ace Director, back in 2019, during KScope Keynote!
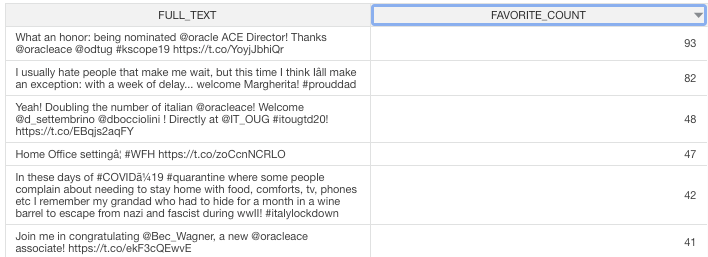
This first visualization is ok, but not really using any of the Oracle Text capabilities exposed in the Tokens... so my next analysis was...
Which words do I use more often when tweeting?Easy... with the two datasources created above!
 How does it change when I reply to people?
How does it change when I reply to people?Well, you can see that words about OUG sessions and Oracle are still there, but there is the emerging topic of Food!
 Who do I interact most with?
Who do I interact most with?I plotted the # of Replies to specific Users…
No wonder (at least to me) that I get the most interactions with people that tag me with Italian food abominations…
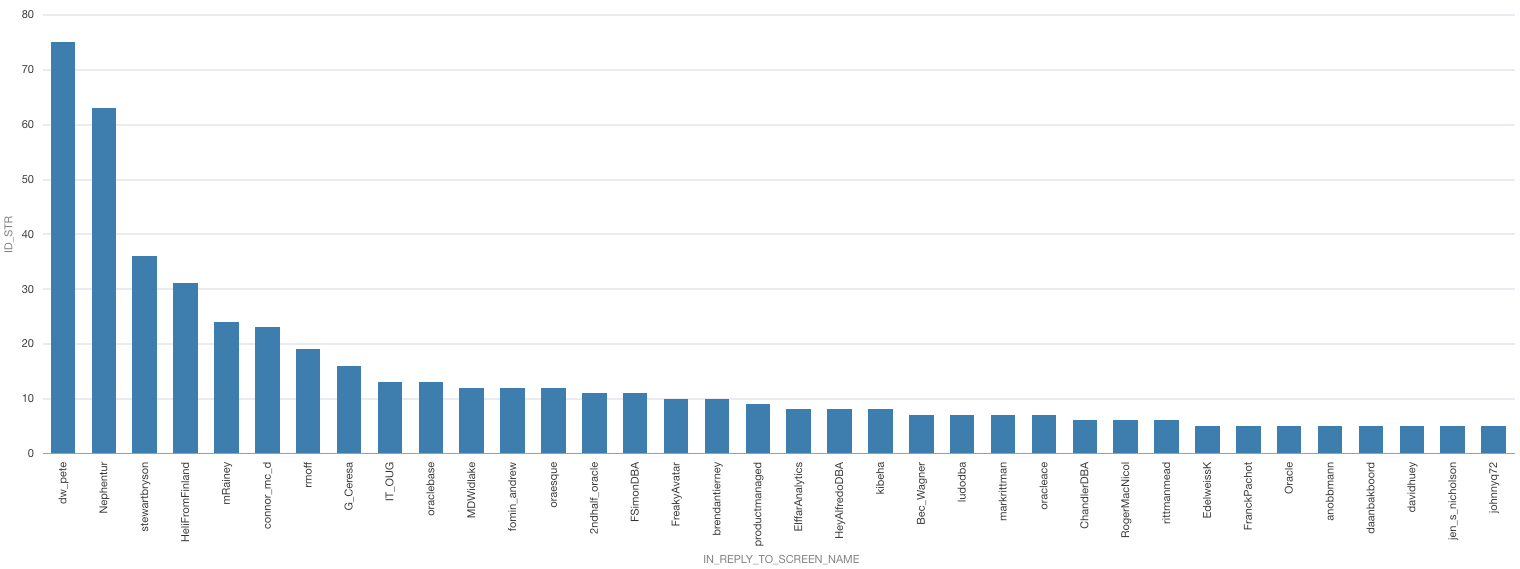 And... how do I reply to them?
And... how do I reply to them?Again, very easy with Oracle Analytics Cloud Trellis Options.
You can spot that Food is the major discussion topic with HeliFromFinland and dw_pete, while my chats with @connor_mc_d and @stewartbryson are covering more topics
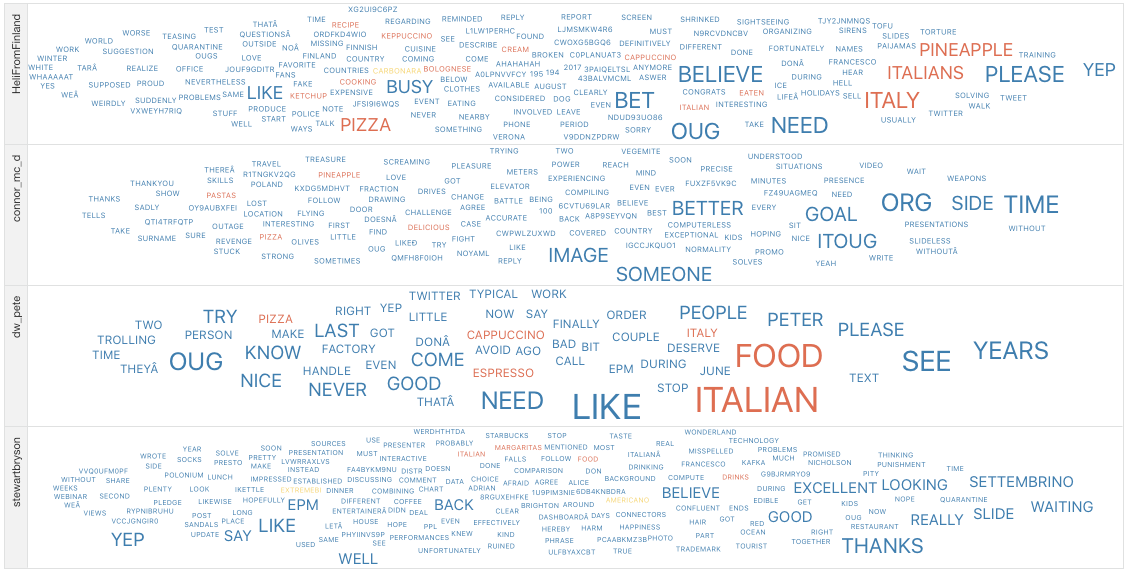 What about Nephentur?
What about Nephentur?One Last mention to my interactions with Nephentur: It’s clear his love for OUGs, Airports, Flights, Hotels… all driven by #TheBergEffect
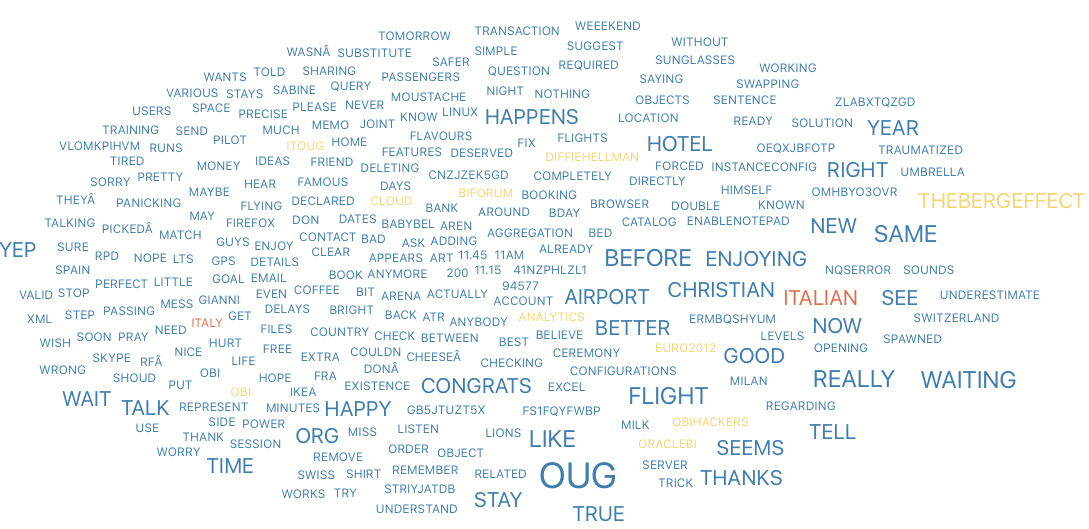
Hope you liked the story, just an example of what you can do with a dataset you own and tools available in the Oracle Cloud!
OA Summit 2020: OA Roadmap Summary

If you are in the Oracle Analytics space, the OA Summit is a great source of content: from Keynotes, customer stories, Partners deep dives; the website is a collection of stories about Oracle Analytics. We've been part of the initial episode talking about how you can start your journey to Data Science with Oracle Analytics!
In Tuesday's session, Gabby Rubin, VP of Product Management, and Jacques Vigeant, Senior Director Product Strategy, shared a series of insights about the product roadmap that we'll cover in this blog.
Public Roadmap & IdeaLabThis is quite big news in the Oracle space, now there is a clear vision about what's coming in the product, accessible by everyone on a public website.
 OA Roadmap and IdeaLab
OA Roadmap and IdeaLabThe public roadmap works well also in conjunction with IdeaLab: a place where everyone in the OA community can suggest new product features and up/downvote or add comments on other people's ideas. These hints are reviewed by Product Managers and, if considered valid, included in future releases of the product!
Converged AnalyticsThe state of the art in the Analytics space offers a neat separation between self-service tools and centralized IT-governed ones. Even for Oracle Analytics, we have two separate approaches as of now: self-service data preparation via Data Visualization vs enterprise IT-driven via RPD.

What was announced at the OA Summit is that the two approaches will converge: there will be the option to self-create a multi-table and multi-source federated dataset which can be shared. This approach empowers the end-user and works on top of the usual self-service data-source definition workflow enabling for each identity in the diagram, ML-based transformations and enrichment recommendations as well as caching setting definitions.
Empowering the end-user also means enabling best software development practices like versioning, certification and promotion capabilities on top of the asset created. The multi-table federated dataset created by end-users will seamlessly transition into enterprise-level semantic models without IT intervention.

From the enterprise side, as announced during OOW19, we'll see a new web-based semantic modeler which will substitute good old Admin Tool. Unlike the current "Lite Data Modeler", the new product will enable the same level of definition complexity we can find in today's RPDs thus will be compatible with every OAC/OAS prebuilt repository. The new web-based semantic modeler is not only a pure replacement of the Windows-based admin tool, but it also offers a native source control integration with Git and in-built options for Data Lineage explorations.

As mentioned the new tool is web-based; if you're an expert RPD developer and worried about different development methodology slowing down the build process, well, there is big news for you! You will be able to edit Repositories via the new JSON based Semantic Modeling Markup Language! Yep, you'll be able to define all the layers of an RPD in JSON syntax, even outside the web-based semantic modeler tool itself. This opens a huge variety of opportunities for source-control, CI/CD pipelines, as well as automatic (coded) builds of RPD artifacts.
Oracle Analytics as Enterprise KeystoneAs briefly described in my Data Virtualization blog post, Oracle Analytics can (and should) be considered the Analytics Keystone in the enterprise: the convergence of IT-driven and self-service metadata models can already be exposed via ODBC in OAS enabling the downstream application to access the data inheriting the security settings defined in the Repository. The OA team is working to offer the equivalent in JDBC format for all Oracle Analytics products!
Oracle Analytics is also enhancing the number of source-system connectors available: we'll soon have the option to connect directly to Oracle EPM Cloud from Data Visualization, and similar connectors are arriving for JDBC sources and Google's Big Query.
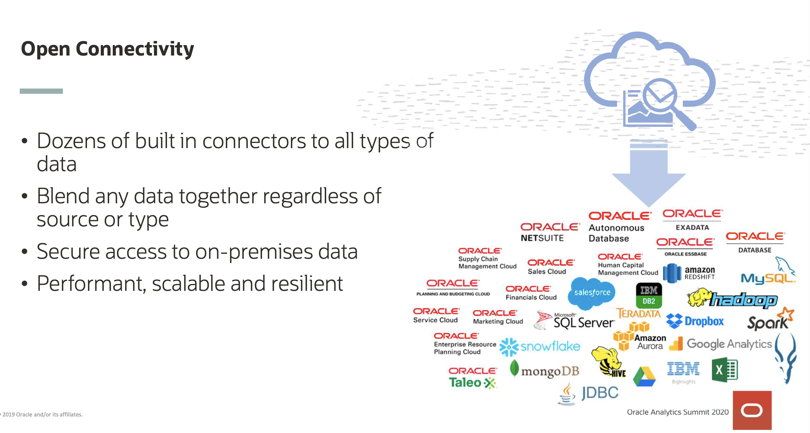 Machine Learning in OA
Machine Learning in OAAugmented Analytics and Machine Learning capabilities have existed for a long time in Oracle Analytics. A new important improvement in this area will enable Data Flows to use Machine Learning models created outside OA via the usual GUI.
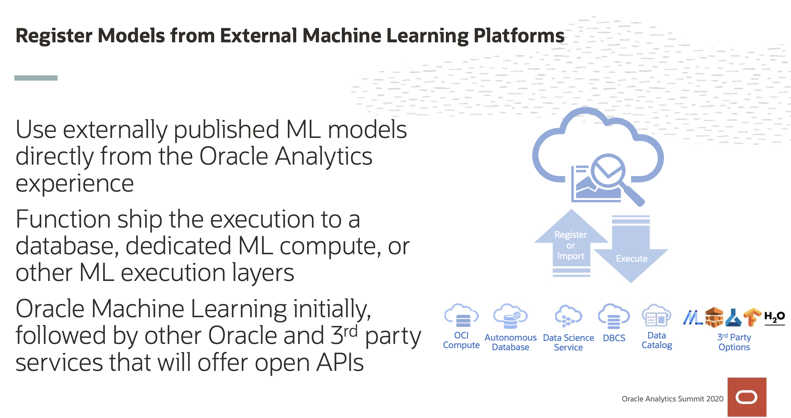
Data Scientists will be able to use their favourite environment and toolset in order to analyse the data and build models. The models built in external systems like Oracle Databases, Oracle Data Science Services, or 3rd-party services could then be registered within OA and used to score data in Data Flows making the Data Scientist and Data Analyst collaboration much easier increasing the ML ubiquity in enterprises.
Predictions explainability will also be possible directly in OA, with details of each model exposed appropriately depending on the model type.
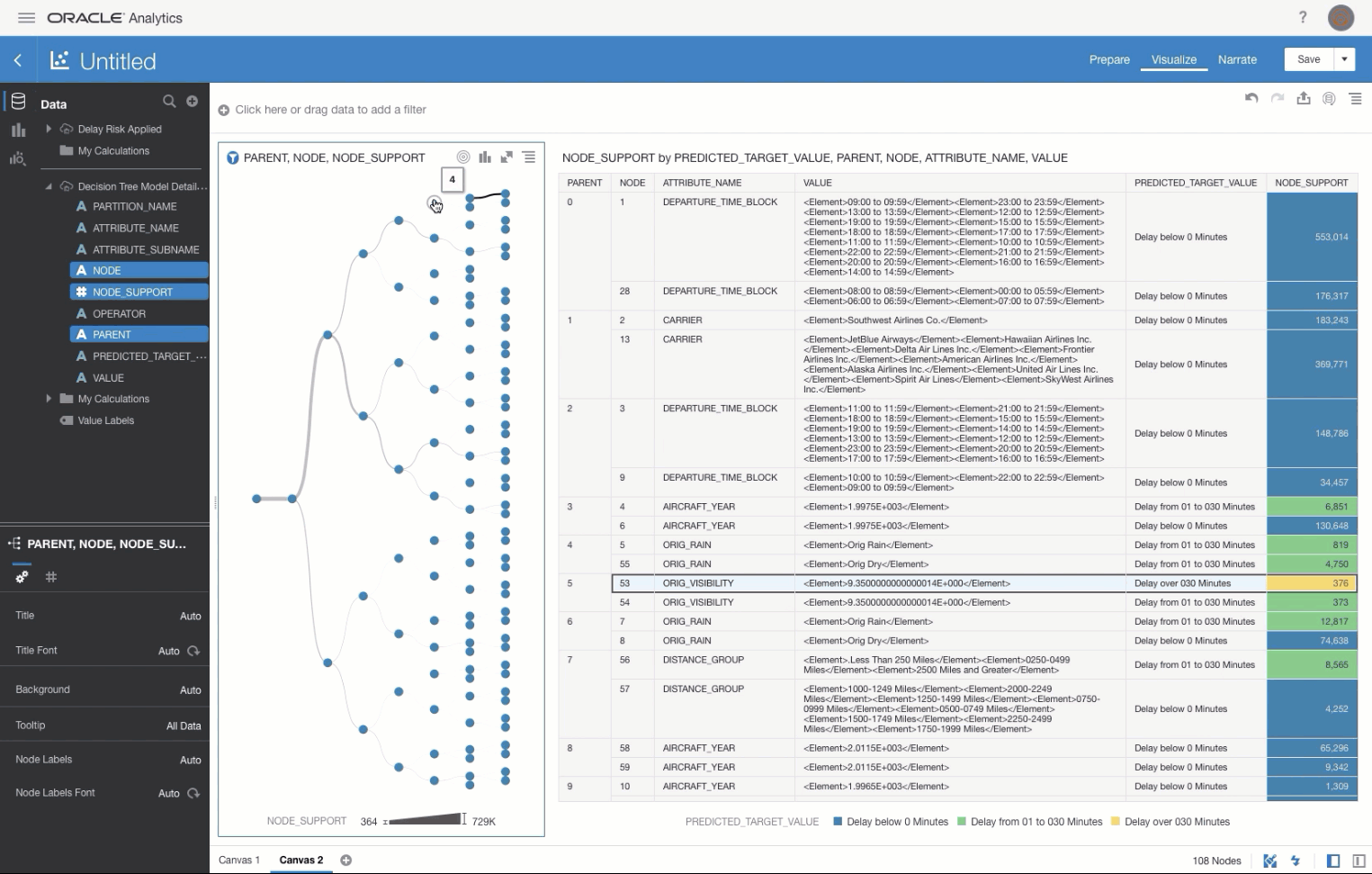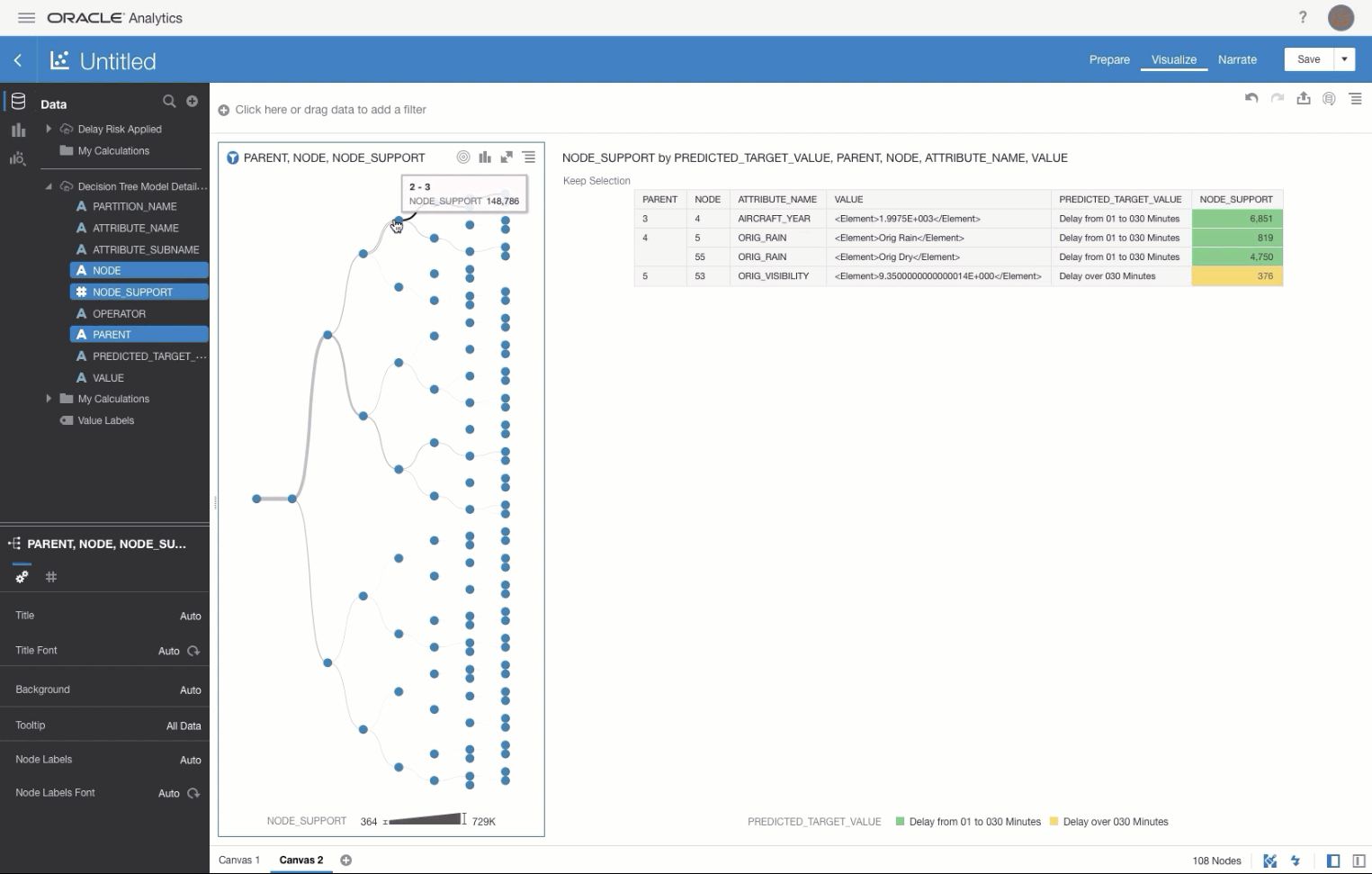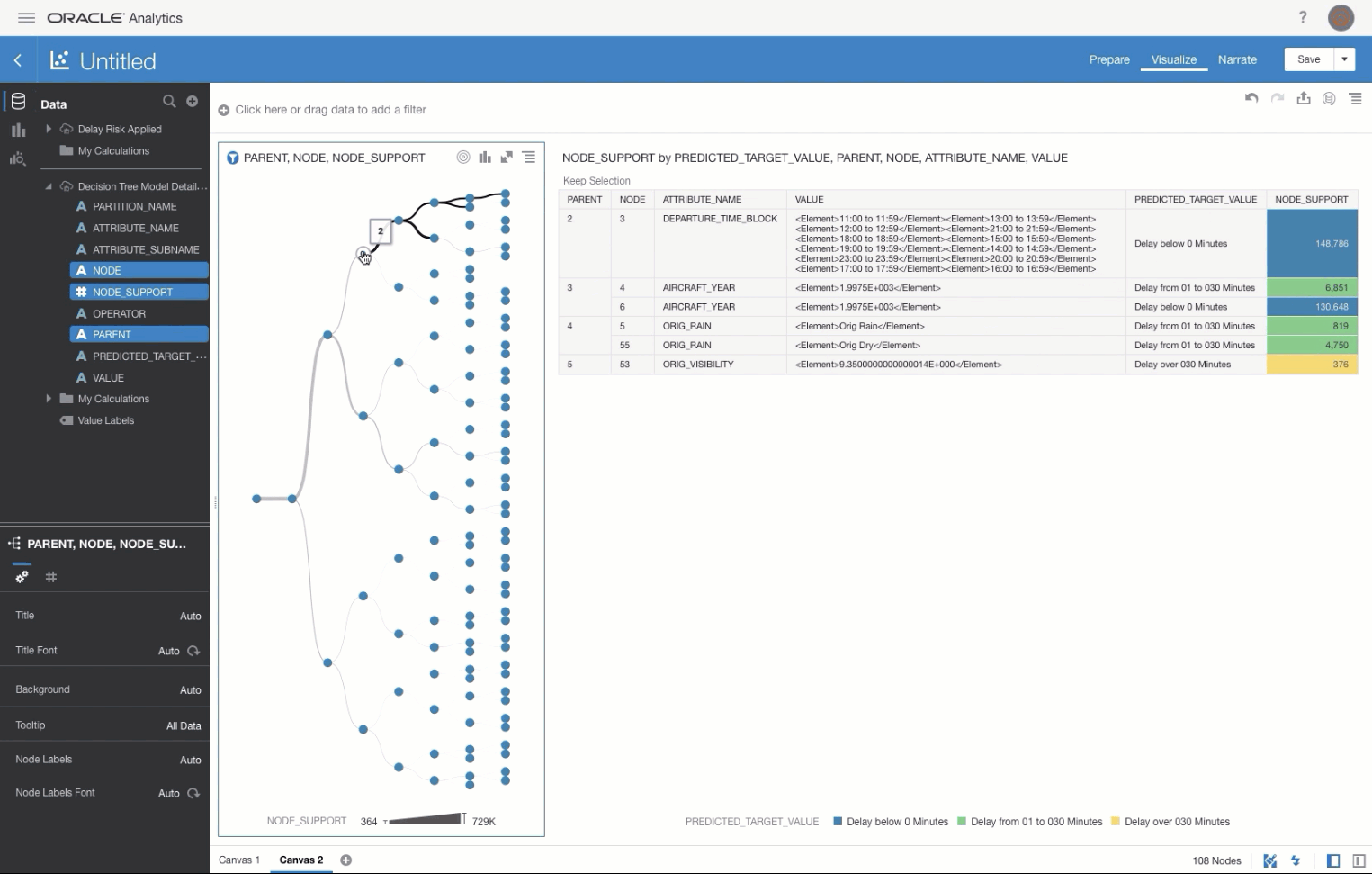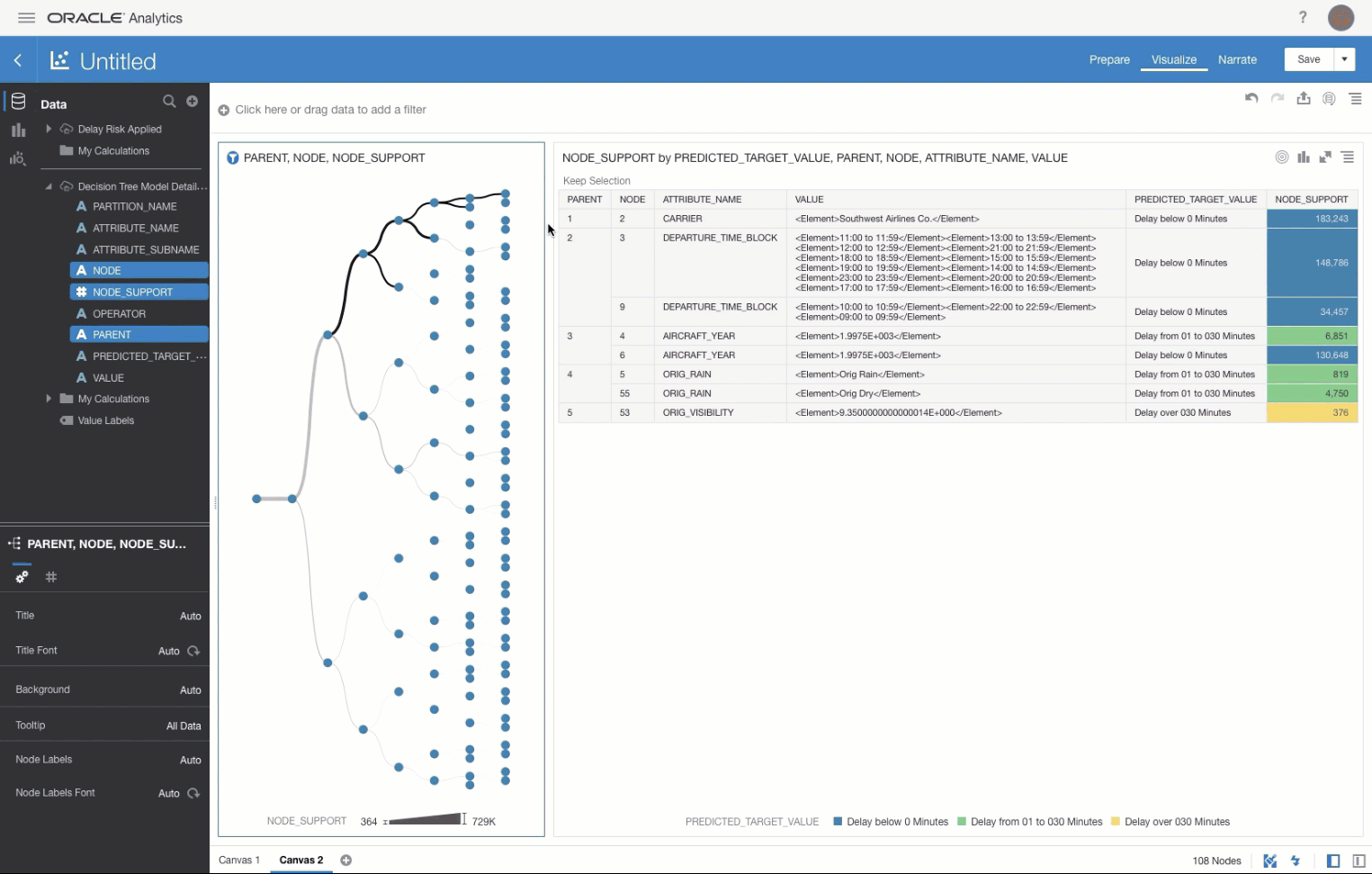
In addition to the above, OA will also allow the usage of Advanced Database Analytics like Sampling, Un-pivoting, Clustering, Anomaly Detection or tokenization with more to come. This allows the usage of already existing functions (avoiding to reinvent the wheel) that can perform securely on massive amounts of data in the Oracle Database.
Data Visualization New FeaturesThere is also some news which has already been shipped in the latest product or will be available soon. Some examples are:
- Adaptive content: we can enable content scrolling in Data Visualization projects, allowing proper spacing of otherwise crowded visualizations
- Canvas Filter control: a prompt that can filter only a subset of analysis registered to it (similar to the Master-details concept in Analysis)
- OAC Embedding Framework: That allows to integrate OA capabilities into external web applications
- Digitalized Map Layers: create an infographic on top of any image, all directly in OAC
 OA on Mobile
OA on MobileWhat about consuming OA content in mobile devices? Data Visualization content is adaptive, the visualization size and appearance will change depending on screen type, so all created content could simply be accessed via mobile browser. Oracle is also investing in Day by Day, which acts as a personal proactive Data Assistant and now enables the threshold-based notifications with more visualization types coming later in the year.
The new announcement regarding mobile is the new Oracle Analytics Mobile App which substitutes the Oracle BI Mobile HD and will provide a way to use, search and collaborate on curated content exposed by OA with an experience in line with modern apps.
More on this, All the Oracle Analytics Apps will enable collaboration: several people will be able to access and comment on visualizations and data avoiding the need to switch to other tools like emails.
A whole new wave of capabilities is in the Oracle Analytics roadmap, for any doubt or questions feel free to reach us!